Obsah
- 1. Úvod
- 2. Specifikace diplomové práce
- 3. Vyhledávání na Internetu
- 4. Obdobné aplikace
- 5. Programátorská dokumentace (implementace)
- 6. Závěr
- Seznam použité literatury
- A. Uživatelská dokumentace
- B. Obsah přiloženého CD
Svět je v současnosti zahlcován velkým množstvím informací (tiskové a jiné zprávy, výpisy, korespondence, příspěvky elektronických konferencí, odborné články a v poslední době už i celé knihy), které je nutno zpracovat a uložit k pozdějšímu použití. Toto zpracování a uložení se naštěstí již převážně provádí v elektronické podobě. Pod pojmem pozdějšího použití se rozumí vyhledávání důležitých informací v těchto archívech.
Naneštěstí neexistuje jednotný formát těchto dat, natož pak jednotné zpracování, archivování a nástroje pro vyhledávání. Existuje nepřeberné množství způsobů (formátů), jak tyto data uložit a další nové formáty vznikají. Tím se hledaní v textech stává komplikovanější protože na každý formát dat existují jiné nástroje. Některé formáty dokonce žádný rozumný způsob prohledávání neumožňují.
Mezi nejčastěji používané zdroje textových dat, se kterými se běžný uživatel počítače setká patří následující.
- E-mailová korespondence a příspěvky elektronických konferencí
Ty jsou uloženy v poštovních klientech (Microsoft OutLook, PegasusMail, Pine, Lotus Notes, …). Data v těchto aplikacích jsou ukládána ve vlastním formátu, který je pro další využití ostatními aplikacemi většinou naprosto nevhodný. Naštěstí většina těchto poštovních klientů umožňuje exportovat data do čistého textu, se kterým se pracuje podstatně lépe.
- Samostatné dokumenty na disku v různých formátech
K většině níže uvedeným formátům existují aplikace pro vyhledávání. Téměř vždy to jsou aplikace ve kterých zmíněné typy dokumentů vznikají. Tyto nástroje jsou omezené pouze na daný formát.
Existuje i několik výjimek, například Microsoft Index Server (součást Internet Information Server a Windows NT Serveru, sloužící pro indexaci a plnohodnotné vyhledávání dokumentů přístupných přes WWW) pracuje s formáty txt, html a s dokumenty kancelářského balíku MS Office.
Čistý text (.txt) - platformě nezávislý, snadno přenositelný a nestrukturovaný (moc se nepoužívá).
Elektronická kniha (.lit) neboli e-Book prohližitelná pomocí Microsoft Reader (ovšem obdobné formáty vyvíjí i jiné firmy, jako například Adobe).
Dokumenty Microsoft Office. (.doc). Velmi nepřenositelné, dokonce se jedná o formát nekompatibilní mezi jednotlivými verzemi Office. Bohužel je velmi oblíben i když podstatně lepší vlastnosti (co do zpracování a přenositelnosti) má Rich Text Format (.rtf). Tento formát se poměrně dosti rozšířil a většina textových procesorů s tímto formátem dokáže pracovat (importovat a exportovat data).
Portable Document Format (.pdf) - platformě nezávislý formát firmy Adobe, který lze prohlížet například pomocí Adobe Acrobat Reader.
Poscript (.ps) - textový soubor popisující vzhled tištěné stránky včetně textu a obrázků. Je podporován nejen výrobci softwaru, ale i hardwaru. Tyto soubory lze v prostředí Windows prohlížet například pomocí Ghost View.
Webové stránky (.htm, .html, .shtml, …) jsou psány jazykem HTML (Hypertext Markup Language). Téměř každý operační systém obsahuje prohlížeč tohoto formátu.
XML (.xml) - univerzální a otevřený formát (Extensible Markup Language) pro výměnu dat. V poslední době velmi oblíbený.
- Informace v databázích
Velké množství textů je uloženo v databázích. Je to jeden z nejlepších způsobů pro uložení dat. Nabízí poměrně snadnou správu dat, umožňuje vyhledávání pomocí SQL příkazů, …
V současné době většina databázových serverů obsahuje buď speciální rozšíření pro ukládání textů (například u serveru Oracle bylo dříve rozšíření ConText Cartridge, nyní Oracle8i interMedia Text) případně alespoň nabízí operátory umožňující rozumně vyhledávat (například v Microsoft SQL Serveru jsou operátory CONTAINS, CONTAINSTABLE , FREETEXT, FREETEXTTABLE).
- Internet
Ovšem nejvíce textů se nachází na Internetu v podobě webových stránek. I v tomto případě existuje způsob pro vyhledávání. Jsou jím různé webové služby (katalogové a fulltextové vyhledávače, hledání v konferencích, …).
Bohužel v současné době neexistuje žádný způsob, jak v těchto uvedených zdrojích informací hromadně vyhledávat. Neexistuje dokonce ani definice jazyka, který by byl jednotný pro specifikaci dotazu. Každá aplikace si proto vytváří vlastní jazyk pro popsání hledaných termů, vztahů mezi nimi, …
V databázových systémech se používá jazyk SQL (Structured Query Language) rozšířený o operátory pro fulltextové hledání, webové vyhledávače používají syntaxi boolské algebry rozšířenou o vlastní operátory pro hledání v různých sekcích, doménách, …
Uživatelé se tak k mnohým důležitým informacím ani nedostanou, protože nejsou schopní (případně jsou již znechuceni) využít a prohledat všechny zdroje dat. A nejsou ani schopni plně využít možnosti, které jednotlivé nástroje nabízí. Většinou se zaměří na několik málo nástrojů., které si více osvojí a tyto používají.
Cílem diplomové práce je vytvořit program, usnadňující vyhledávání informací v dokumentech, jež jsou uloženy na rozličných místech a v různých formátech. Jedná se tedy o program podobný webovému metavyhledávači (viz oddíl nazvaný „Metavyhledávače“) nebo spíše klientskému vyhledávači (viz oddíl nazvaný „Klientské vyhledávače“), ovšem s tím rozdílem, že nebude oslovovat pouze webové vyhledávací stroje, ale i další libovolné zdroje dat (Oracle a jiné databáze, soubory na lokálním disku, …).
Množina zdrojů, které se budou pro vyhledávání používat, půjde snadno rozšířit o další a to bez nutnosti rekompilace aplikace. Navíc toto rozšíření zdrojů bude umožněno komukoliv - bude implementováno v nezávislém modulu, který bude sloužit pro komunikaci mezi příslušným fyzickým serverem a aplikací.
Hlavní náplní je tedy navrhnout a implementovat rozhraní mezi aplikací a vlastním DIS serverem (který bude oslovován) tak, aby umožnilo uživateli:
Obsah
Vyhledávání informací na Internetu se dá rozdělit do několika kategorií podle použitých nástrojů:
Katalogové vyhledávače jsou postaveny na velké databázi stránek, která má stromovou strukturu. Jednotlivé odkazy jsou roztříděny do několika (řádově deseti) základních kategorií, které se dále dělí na podkategorie a tak dále.
Uživatel může tyto služby využívat dvojím způsobem:
Mezi nejznámější katalogy u nás patří:
Seznam (http://www.seznam.cz) - první katalog u nás, nejznámější a nejnavštěvovanější
Atlas (http://www.atlas.cz)
Centrum (http://www.centrum.cz)
Quick (http://search.quick.cz)
RedBox (http://www.redbox.cz)
V zahraničí jsou asi nejznámější:
DMOZ (http://dmoz.org) - Open Directory Project
Yahoo (http://www.yahoo.com)
Excite (http://www.excite.com)
Lycos (http://dir.lycos.com)
Google (http://directory.google.com)
Na rozdíl od katalogových vyhledávačů se stránky v jejich databázích nedají sekvenčně procházet. Umožňují pouze nalézt relevantní stránky odpovídající zadanému dotazu.
Většina vyhledávačů tohoto typu používá „Boolovský model“. Jedná se o jeden z nejstarších modelů DIS, jehož základy byly navrženy již v 50-tých letech. Každý dokument modelu obsahuje množinu slov a vyhledávání je založeno na vyhodnocování boolovských výrazů (AND, OR, NOT) jak je uvedeno v 1 a 2.
Například dotazem Z AND (X OR Y) se naleznou dokumenty obsahující slovo Z a alespoň jedno ze slov X nebo Y.
Tento model lze dále rozšířit o operátory vzájemné polohy termů v dokumentu (například term X musí být maximálně ve vzdálenosti 10 slov od termu Y, případně ve stejném odstavci, stránce, kapitole, …).
Hlavní nevýhodou boolovského modelu je nemožnost ohodnotit slova (určit, která slova jsou důležitá a která nikoliv. Typicky běžná slova, jako například „který“, „kolem“ a podobně, jsou v článku o JavaScriptu podstatně méně důležitá než „toString“, „getDate“, …) a to jak v dotazu, tak v samotném dokumentu, což má několik špatných důsledků:
Nelze ohodnotit nalezené záznamy dle relevance (všechny dokumenty, které odpovídají dotazu jsou stejně dobré)
Termy v dotazu i dokumentu jsou chápány jako stejně důležité
Neintuitivní výsledky (T1 OR T2 OR … OR Tn - vrátí záznamy se všemi Ti ale i takové, které obsahují jediné Ti. T1 AND T2 AND … AND Tn - ve výsledku nebudou záznamy neobsahující jediný Ti)
Fulltextové vyhledávací stroje se skládají z několika částí:
Jinak zvaní též „spiders“, „worms“ či „web crawlers“ jsou programy, které procházejí web a indexují nalezené stránky. Pod pojmem Indexace se rozumí zpracování obsahu stránky - tedy zapsání důležitých klíčových slov stránky (a dalších informací) do databáze.
Kromě hledání nových stránek mají za úkol prověřovat aktuálnost databáze. To jest kontrolují, zda v ní obsažené dokumenty, jsou stále ještě přístupné a zda jejich obsah odpovídá uloženým informacím. Během jednoho dne stihnou tyto programy navštívit několik milionů stránek.
Některé fulltextové vyhledávače umožňují návštěvníkům vložit vlastní stránky do databáze (jiné toto neumožňují a spoléhají pouze na své roboty). Samozřejmě, že se při přijmutí požadavku neprovede zápis přímo do databáze, ale uvedená adresa se podstrčí robotovi, který ji zpracuje jako ostatní stránky.
Roboti kromě zapsání informací o stránce zjistí také adresy, na které se odkazuje a vloží je do fronty odkazů, které později zpracuje (navštíví a naindexuje). Je tedy zřejmé, že čím více odkazů na stránku ukazuje, tím dříve bude nalezena a zařazena do indexu. Pokud na stránku neexistuje žádný odkaz, nebude nalezena nikdy a pokud nebude zařazena do databáze ručně, může se stát, že nebude nikdy naindexována. Díky tomu, že se indexování provádí automaticky, existují stránky, které nemohou být nikdy zařazeny do databáze. Jsou to zejména:
Obsahuje informace o naindexovaných stránkách. Kromě seznamu klíčových slov (termů), které stránka obsahuje, se můžou ukládat i jiné informace: pořadí slov, zda slova tvoří nějakou známou frázi, datum modifikace stránky, linky z této stránky a na tuto stránku, informace o serveru, kde se stránka nachází, zda je mládeži přístupná atd. Záleží na implementaci daného systému. Čím více informací se ukládá, tím více možností má uživatel při zadávání dotazu a také při prohlížení výsledků.
Základní možnosti, které fulltextové vyhledávače podporují (viz 4 a 5) jsou:
Vyhledávání frází (slova, která se v hledaném dokumentu musí vyskytovat u sebe). Při zadávání se používají uvozovky.
Podpora základních operátorů: AND, OR, NOT, NEAR (spojuje slova, která by se v dokumentu měla vyskytovat blízko sebe). Některé stroje tyto operátory zjednodušují na znaménkový prefix:
Většinou je možné místo těchto operátorů psát jejich zkratky ( &, |, !, ~).Podpora žolíků „*“ slouží pro nahrazení libovolného počtu písmen (někdy je z důvodu optimalizace umožněno použít žolíka pouze v případě, že je zadán jistý počet písmen. Navíc je někdy povoleno používat žolíky pouze jednostranně, to jest že představují jen libovolnou koncovku, případně předponu).
Omezení počtu výsledků z jednoho serveru. Stránky na jednom serveru mají většinou velmi podobný obsah (zaměření). Takto lze získat více relevantních stránek z více serverů (z každého serveru se vybere pouze jedna (nebo několik málo) nejrelevantnější stránka).
Slova v různých sekcích stránky (text odkazu, název obrázku, odkaz, adresa, název).
Obsahuje-li hledané termy v názvu stránky (HTML tag <TITLE>).
Počet nalezených slov a jejich výskytů v textu (čím více z hledaných slov dokument obsahuje, tím má lepší ohodnocení). Proto je rozumné zadávat v dotazu hodně podobných termů.
Obsahuje-li více slov, které jsou označeny znaménkem „+“ v dotazu.
Obsahuje-li slova, která byla nalezena na relativně málo jiných stránkách.
Zda dokument obsahuje některá slova jako frázi, ač tato slova nebyla v dotazu uvedena v uvozovkách (například často hledané spojení typu „Bill Gates“ a podobně).
Kompas (http://kompas.seznam.cz) - Součást nejznámějšího českého katalogu Seznam.
Megatext (http://www.megatext.cz) - Chlubí se, že patří mezi největší a technologicky nejpokročilejší fulltextové vyhledávače u nás. A to zejména díky tomu, že se jako jediný z velkých českých vyhledávačů dokáže plně vypořádat s klíčovými problémy složité české gramatiky (viz 10). Umí vyhledávat česká ohýbaná slova ve všech jejich morfologických tvarech. Má pro řešení tohoto problému k dispozici rozsáhlý slovník 50-ti tisíc nejfrekventovanějších českých slov, s jehož pomocí dokáže hledané výrazy spolehlivě identifikovat bez ohledu na to, v jakém pádu, čísle nebo slovesném čase se daný termín na stránce vyskytuje.
Atlas (http://hledej.atlas.cz)
Redbox (http://www.redbox.cz)
Altavista (http://www.altavista.com) - Jeden z prvních a nejlepších fulltextů vůbec. Bohužel v poslední době upadá a je pomalý. Na druhou stranu obsahuje několik zajímavých služeb (hledání obrázků, hudby a multimédií, překlad do jiných jazyků, čistě textová verze, …)
Google (http://www.google.com) - V poslední době asi nejpoužívanější (obsahuje zajímavé vylepšení prohlížeče - přídavná lišta pro rychlé vyhledávání)
Excite (http://www.excite.com)
All The Web (http://www.alltheweb.com)
MSN (http://www.msn.com)
Metavyhledávač je vyhledávací stroj, který využívá ostatní vyhledávače. Po zadání dotazu jej předá vyhledávačům (většinou jich bývá několik), které jej paralelně vyhodnocují, počká si na výsledky a zpracuje je (setřídí, odstraní duplicitní odkazy, zobrazí výsledky v jednotném formátu, …).
Bohužel ne každý vyhledávač na webu, který o sobě tvrdí že je metavyhledávač, jím skutečně je. Většinou se jedná jen o stránku umožňující zadat dotaz na několik serverů, ale výsledky jednotlivých vyhledávačů se zobrazí na samostatných stránkách, takže základní a nejtěžší funkce (zpracování a sjednocení výsledků z různých zdrojů) není u nich implementována.
Mezi základní výhody těchto systémů patří množství naindexovaných stránek (je to podstatně více než mají normální vyhledávače), uživatelská přívětivost (jednotný interface), rychlost (paralelní zpracování).
U nás existuje zatím jediný metavyhledávač:
Archon (http://www.archon.cz)
Search.com (http://www.search.com)
Apollo 7 (http://www.apollo7.de)
Meta Crawler (http://www.metacrawler.com)
Monster Crawler (http://www.monstercrawler.com)
Search Caddy (http://www.searchcaddy.com)
Další možností, jak hledat informace na Internetu, jsou takzvané klientské vyhledávače. Jedná se o aplikace nainstalované na lokálním disku, které pro vlastní vyhledávání používají několik (až několik desítek) různých katalogových, fulltextových a jiných vyhledávačů. Jde tedy vlastně o metavyhledávače, které mají podobu klasické aplikace.
Výhod těchto systémů je několik:
Uživatelské prostředí - jelikož se jedná o aplikaci a ne o webovou stránku, může se spousta rysů velmi snadno nastavit a toto nastavení uložit (což ne každý vyhledávač podporuje).
Podstatně rychlejší start - aplikace je nainstalována na lokálním disku a na rozdíl od webového vyhledávače není třeba před vlastním vyhledáváním nic stahovat.
Většina těchto programů uchovává historii vyhledávání včetně výsledků (seznamu nalezených dokumentů). Uživatel se tak může snadno vrátit k předchozím dotazům a tyto dotazy dále „ladit“.
Další služby - generování reportů, možnost automatického skenování (hledání změn, novinek, dalších dokumentů, …)
BullsEye (http://www.intelliseek.com/prod/bullseye/bullseye.htm)
Copernic (http://www.copernic.com/)
Babylon (http://www.babylon.com/)
Obsah
Aplikace, která je součástí diplomové práce, se nejvíce podobá klientským vyhledávačům. V současné době je jich několik na trhu. Převážně se jedná o sharewarové produkty, s omezenou funkčností (jsou zakázané pokročilejší operace, nelze použít všechny vyhledávací služby, ale pouze některé, …).
Níže následuje bližší popis několika aplikací (viz 3), kterými byla ovlivněna tvorba programu DISClient. Existuje i spousta dalších produktů (Webferret, Search+, …). Ty však nedosahují takových kvalit a možností, proto zde nebudou uvedeny.
Copernic 2001 je klasický desktopový vyhledávač, jenž pro vlastní vyhledávání využívá asi 80 webových vyhledávacích strojů. Aktuálnost je zajišťována automatickým updatem nastavení vyhledávacích serverů při startu aplikace či vyhledávání. Uživatel se tak nemusí o nic starat (případně může to samé provést příkazem z menu).

Vzhled aplikace (Obrázek 4.1.) je víceméně standardní - v levé části seznam kategorií, vpravo seznam dotazů, pod ním přehled nalezených dokumentů k aktuálnímu dotazu a v levém dolním rohu malý náhled vybraného dokumentu.
Při práci je nejdříve třeba vybrat oblast, ve které se bude hledat. K výběru nabízí aplikace více než 40 kategorií. V neregistrované verzi je k dispozici pouze prvních 6 - web, diskusní fóra, emailové adresy, nákup knih, hardwaru a softwaru. Po registraci se nabídka rozšíří o mnoho dalších (aukce, zdraví, humor, obrázky, filmy, MP3, recepty, věda, cestování, sport a podobně), jiné naleznete na stránkách výrobce (http://www.copernic.com/downloads/categories/).
Po zvolení kategorie je nutno zadat vlastní dotaz. To spočívá v zadání několika termů a zvolení vztahu mezi těmito termy a hledanými dokumenty: zda dokumenty musí obsahovat všechna slova, zda postačí alespoň jedno nebo zda se jedná o přesnou frázi. Zajímavou volbou je mód „Odpověď na otázku“, kdy se místo klíčových slov napíše otázka celou větou a program už si to sám převede (například „Where was Albert Einstein born?“). Zde je nutno podotknout, že celý program je anglicky, používá zahraniční vyhledávače a tedy je nutné tuto otázku položit v angličtině. Také lze upravit seznam vyhledávačů, které se pro vlastní hledání použijí.
Plná verze programu umožňuje automatické odstranění nedosažitelných dokumentů. Vyhledávání pak sice trvá déle (kontroluje se existence nalezených dokumentů), ale uživatel má jistotu, že nalezené dokumenty jsou dostupné.
Posledním krokem editace dotazu je zadání maximálního počtu výsledků od jednotlivých vyhledávacích strojů a počet výsledků celkem.
Po potvrzení se program pustí do vlastního vyhledávání. Průběh se zobrazuje v pomocném dialogu, kde se také vypisuje kolik dokumentů bylo nalezeno jednotlivými kontaktovanými vyhledávači. Výsledky (odpovídající dokumenty) se poté zobrazí v přehledném seznamu.
Nalezené dokumenty lze samozřejmě prohlížet - pro zobrazení lze využít jakýkoliv nainstalovaný prohlížeč a nebo interní prohlížeč této aplikace, který dovede navíc ve zobrazovaném dokumentu zvýraznit hledaná slova, snadno přecházet mezi jednotlivými dokumenty a obsahuje i příjemné klávesové zkratky. Ve stejném prohlížeči lze také zobrazit seznam nalezených dokumentů, což se velmi podobá prohlížení výsledků na běžném webovém fulltextu. Vybrané dokumenty lze kromě prohlížení také uložit na disk (včetně obrázků, či bez nich).
Zajímavá je také možnost zobrazit si dokument v jiném jazyce (stačí zadat z jakého do jakého jazyka se má přeložit). K dispozici je angličtina, francouzština, němčina, italština, japonština, portugalština a španělština.
Ve fázi specifikace dotazu sice nelze odfiltrovat nefunkční odkazy (tedy ve freewarové verzi programu), ale po prohledání již toto naštěstí provést lze.
Je-li navrácených dokumentů přespříliš, lze je filtrovat. K tomu slouží příkaz Refine, který zkontroluje, zda vybrané dokumenty opravdu obsahují uživatelem zadaná slova (předtím se automaticky stáhnou na pevný disk). Přitom je možné poupravit slova, která má dokument obsahovat (k dispozici jsou spojky AND, OR, EXCEPT, NOT, NEAR) a tedy dotaz takto doladit.
Přehled nalezených dokumentů odpovídající dotazu se dá vyexportovat v několika různých formátech: čistý text, HTML, CSV (Comma Separated Value - atributy jsou odděleny čárkami - formát podporovaný třeba Excelem), DBF a XML.
Výsledky jednotlivých vyhledávání se ukládají na disk, do speciálních adresářů, které lze snadno editovat. Díky tomu se k nim může uživatel kdykoliv později vrátit a dále s nimi pracovat: pozměnit dotaz, znovu vyhledat (přidají se pouze nově nalezené dokumenty), duplikovat a podobně.
Aplikace lze vizuálně upravovat - od zobrazování/schovávání jednotlivých prvků, přes sloupečky seznamů, nastavení výchozích voleb při editaci dotazu až po vlastní skiny.
Při instalaci (případně později v nastavení) tohoto produktu je možno zabudovat několik rozšíření do Internet Exploreru: Přidání odkazu do nástrojové lišty a menu, nové položky do kontextového menu prohlížeče, nahrazení standardního nástroje pro vyhledávání, přidání volby překladu stránek.
Ačkoliv je freewarový produkt odlehčenou (chybí mu několik příjemných funkcí) verzí placeného produktu, je plně funkční. Placená verze „Copernic Plus“ obsahuje navíc přístup k 1000 vyhledávacích strojů v 93 kategoriích a neobsahuje reklamní proužky. V ještě dražší verzi „Copernic Pro“ je k dispozici několik nových funkcí (automatické odstraňování nefunkčních odkazů, vyhledávácí agenti, e-mailové upozornění na nové dokumenty odpovídající dotazu a mnohé další).
Klady:
Zápory:
Tabulka 4.1. Informace o aplikaci Copernic 2001
| Název a verze | Copernic 2001 Basic, verze 5.01 |
| Adresa | http://www.copernic.com |
| Výrobce | Copernic Technologies Inc. |
| Typ | Freeware |
| Cena | Freewarová verze - $0, Copernic PLUS - $39.95, Copernic PRO - $79.95 |
| Požadavky | 486DX 66 MHz (a vyšší), 15 MB RAM, 10 MB volného místa na disku, operační systém Microsoft Windows 95/98/Me/NT4/2000/XP, prohlížeč Netscape 3 (a novější) nebo Internet Explorer 3 (a novější). |
Bulls Eye 2 je přímo „Desktopový vyhledávací portál“. Hlavní okno je rozděleno na několik částí (Obrázek 4.2.): Seznam výsledků, náhled aktuálně vybraného dokumentu v tomto seznamu a přehled kategorií, ve kterých je možno vyhledávat - nachází se na levé straně a obsahuje jednotlivé typy vyhledávání: Web, News, Jobs, Books, Software, Health a mnoho dalších.

Po vybrání kategorie při vytváření nového dotazu je třeba zadat hledané termy (k dispozici je přehled dříve zadávaných termů). V pokročilém módu lze využít rozšířené nastavení, kde lze vytvořit podstatně komplikovanější dotazy za pomoci operátorů AND, OR, NOT, NEAR. Je možné si také prohlédnout a případně pozměnit seznam vyhledávacích webových serverů, které se budou používat a nastavit další parametry (kolik maximálně výsledků získat od každého stroje, podle čeho mají být výsledky setříděny).
Podle vybrané kategorie lze blíže specifikovat kde se má hledat (například při vyhledávání knih lze určit, zda se termy týkají názvu, autora, ISBN, zda se hledá knížka v obchodech nebo v knihovnách nebo zda chce uživatel najít volně stažitelnou knihu, …).
Posledním krokem je volba způsobu analýzy dokumentů - žádný, odstraňování neplatných odkazů nebo kontrola, zda dokument opravdu odpovídá zadanému dotazu (v tom případě je samozřejmě nutné dokument nejdříve stáhnout na lokální disk a prozkoumat, což se provede automaticky).
Po potvrzení dotazu začne probíhat vlastní vyhledávání a v seznamu nalezených dokumentů se začnou zobrazovat první výsledky (časem se dotáhnou a správně zařadí zbývající). V seznamu se uvádí základní informace o nalezených dokumentech (relevantnost, adresa, název stránky, jméno vyhledávače, který ji nalezl, …) po přepnutí do detailního módu se zobrazí další informace (datum, velikost a stav dokumentu). Po odkliknutí dokumentu se tento načte a zobrazí pod seznamem s výsledky. Lze nastavit aby rámec s dokumentem případně se seznamem byl přes celé okno nebo aby byly vidět výsledky a dokument zároveň.
Další možností je otevírat výsledky v asociovaném webovém prohlížeči. Samozřejmostí je zvýraznění hledaných slov v prohlíženém dokumentu a tlačítko pro přidání odkazu do záložek.
Za zmínku stojí také informační přehled vyhledávačů, kam se dotaz posílal, ve kterém je uvedeno které servery nic nevyhledaly a hlavně proč tomu tak je (nic nenašly, nepodařilo se na ně připojit, jsou mimo provoz, …).
Z vybraných dokumentů si může uživatel vygenerovat report. Při jeho tvorbě je na výběr několik výsledných formátů (html, čistý text, …). Výsledek se buď uloží na disk, nebo pošle elektronickou poštou.
V levé části okna, kde se vybírá kategorie vyhledávání, se nalézá ještě několik položek. V jedné z nich je seznam právě otevřených projektů (maximálně tři), v další je položka obsahující záložky (a to od obou nainstalovaných internetových prohlížečů - tedy jak Netscape tak MSIE), uložené projekty a již výše zmíněné reporty a historie dotazů.
Další záložka - Track - slouží k automatickému vyhledávání nových dokumentů, které odpovídají zadanému dotazu. Toto je už ale bohužel rozšíření placené verze této aplikace (BullsEye 2 Pro). Odlehčená verze, která je zdarma, zobrazuje reklamní bannery a až na několik náročnějších rozšíření je plně funkční.
Instalace BullsEye 2 přidá několik „zástupců“ do operačního systému pro snazší a rychlejší spouštění aplikace. Konkrétně do nástrojové oblasti hlavní lišty (tool tray), do panelu nástrojů nainstalovaných prohlížečů (MSIE, Netscape) a do Start menu (Start/Search).
Jednou za čas (řádově několik dní) se aplikace zeptá uživatele, zda nemá zkontrolovat výskyt nových aktualizací a případně nabídne jejich stažení a instalaci.
Klady:
Zápory:
Tabulka 4.2. Informace o aplikaci Bulls Eye 2
| Název a verze | Bulls Eye 2, verze 2.5 |
| Adresa | http://www.intelliseek.com/prod/bullseye/bullseye.htm |
| Výrobce | IntelliSeek Inc. |
| Typ | Bulls Eye 2 - Freeware, Bulls Eye 3 Pro - Free Trial (15 dní) |
| Cena | Freewarová verze - $0, Bulls Eye Plus - $49.99, Bulls Eye 3 Pro - $199 |
| Požadavky | Pentium 300 MHz (a vyšší), 64 MB RAM, 100 MB volného místa na disku, operační systém Microsoft Windows 98/ME/2000/NT 4.0 (SP6), prohlížeč Internet Explorer 5.01 SP1 (a novější). |
Babylon je se od výše uvedených dvou aplikací poměrně liší, ale stále jde o desktopový vyhledávač, který ale využívá encyklopedie, slovníky a glosáře. Je to interaktivní program, který okamžitě po kliknutí na slově v libovolné windows aplikaci zobrazí příslušnou informaci o tomto výrazu („instant information @ a click“).

Po instalaci se aplikace usídlí v nástrojové liště a čeká, až jej uživatel vyvolá kláveso-myší zkratkou - pravé nebo prostřední tlačítko myši plus případný přepínač (Ctrl, Alt, Shift) - nad slovem, které chce objasnit. Může se jednat o zkratku, cizí slovo, neznámý výraz, název a podobně. Toto slovo se může vyskytovat kdekoliv - ve Wordu, Zápisníku, v libovolném dialogu, ba dokonce jako název tlačítka či okna. Po kliknutí se objeví malé okno (Obrázek 4.3.), ve kterém se program pokusí objasnit význam daného slova za použití dostupných glosářů.
Kromě glosářů využívá i slovníky překládající mezi hlavními jazyky. Seznam slovníků a glosářů, se nachází na webu výrobce (http://www.babylon.com/gloss/), kde jsou přehledně roztříděné do jednotlivých kategorií a podkategorií.
Mezi další funkce, kterými tato aplikace disponuje, patří převody jednotek, zahraničních měn, časových pásem (byl-li například vyvolán nad heslem „24 cm“ nabídne ihned konverzi centimetrů na jiné délkové jednotky) a správná výslovnost zkoumaného slova.
Primární glosáře a slovníky (ty, které se použijí při prvním vyhledávání významu zkoumaného slova) lze využívat i bez stahování (stačí si je zaregistrovat). Pokud jsou uložené na disku, pracuje program i bez připojení na Internet - uživatel tím získá rychlejší vyhledávání, ale přijde o nejaktuálnější změny a místo na disku).
Jednotlivé glosáře lze tedy přidávat, ubírat, pokud jsou jen zaregistrované, tak i stáhnout na disk, deaktivovat je a později znovu aktivovat, ohodnotit, případně rovnou napsat autorovi několik poznámek.
Nestačí-li nabízené slovníky, je možnost vytvořit si vlastní a dát jej ostatním k dispozici. K tomu je zapotřebí pouze Babylon Builder, který je zdarma dostupný na stránkách tohoto produktu.
Nebylo -li hledané slovo nalezeno v žádném slovníku (případně není-li uživatel s výsledkem spokojen), může ještě zkusit štěstí v hledání pomocí webových vyhledávačů, které jsou také k dispozici. Výsledkem je zobrazení stránky s výsledky v internetovém prohlížeči.
Nalezené výklady hledaných slov lze pro pozdější použití uložit do speciální složky a snadno se k nim vrátit.
Klady:
Zápory:
Tabulka 4.3. Informace o aplikaci Babylon
| Název a verze | Babylon, verze 3.1b |
| Adresa | http://www.babylon.com |
| Výrobce | Babylon Ltd. |
| Typ | Free Trial verze, 30 dní |
| Cena | Babylon-Pro $17.95 |
Obsah
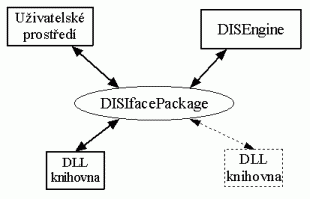
Původní návrh aplikace byl poměrně jednoduchý a počítal s tím, že se vlastní program bude skládat z uživatelského prostředí a DLL knihoven, které budou sloužit pro komunikaci s jednotlivými servery (Obrázek 5.1.).
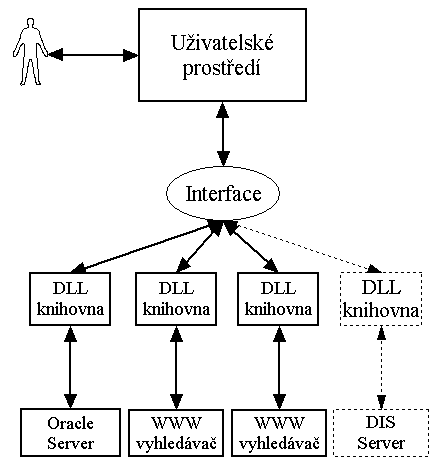
Tyto knihovny budou napojeny na cílové DIS servery, případně webové vyhledávací služby typu Altavista, Google, Serge a další. Propojení mezi vlastním uživatelským prostředím a DLL knihovnami zajišťuje společný interface obsahující základní objekty pro komunikaci.
Aby byl systém dále snadno rozšiřitelný, budou DLL knihovny linkovány dynamicky, tedy pro rozšíření možností aplikace o další cílový server stačí dodat příslušnou DLL knihovnu implementující funkce rozhraní (zejména jde o definici parametrů nastavení serveru, dotazu, vlastní vyhledávání, získání dokumentu, definování způsobu zobrazení dokumentu atd.).
Později se tato architektura ukázala nevýhodná zejména z důvodu dalšího využití. Proto byla vlastní aplikace rozdělena do dvou modulů (Obrázek 5.2.).
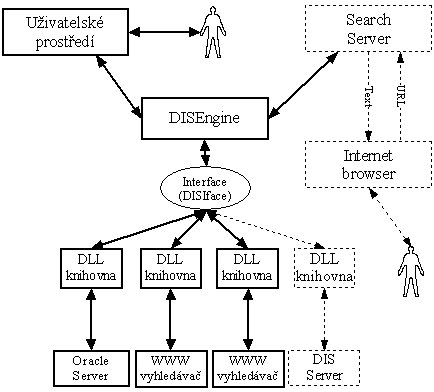
- DISEngine
Vlastní jádro, které se stará o komunikaci s DLL knihovnami, vytvoření dotazu využívající zadané servery, vyhledávání příslušných dokumentů na základě parametrů dotazu, ukládání a načítání dotazů a dokumentů na disk, …
- GUI
Grafické uživatelské rozhraní zajišťuje komunikaci s uživatelem. Jedná se o přívětivé uživatelské prostředí, které zpřístupňuje uživateli aplikace veškeré možností jádra (DISEngine). V budoucnu místo tohoto modulu může být implementován jiný.
Rozhraní (interface) mezi jádrem aplikace (DISEngine) a uživatelským prostředím tvoří knihovna definující objekty, které si tyto moduly předávají.
Prapůvodní interface byl značně jednoduchý a nedomyšlený (Obrázek 5.3.).
Finální verze rozhraní obsahuje mnoho nových objektů, které se v první verzi nevyskytovaly (Obrázek 5.4. a 5.5.). Bližší vysvětlení funkcí jednotlivých komponent rozhraní následuje v dalším textu.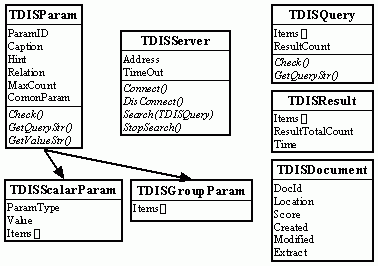
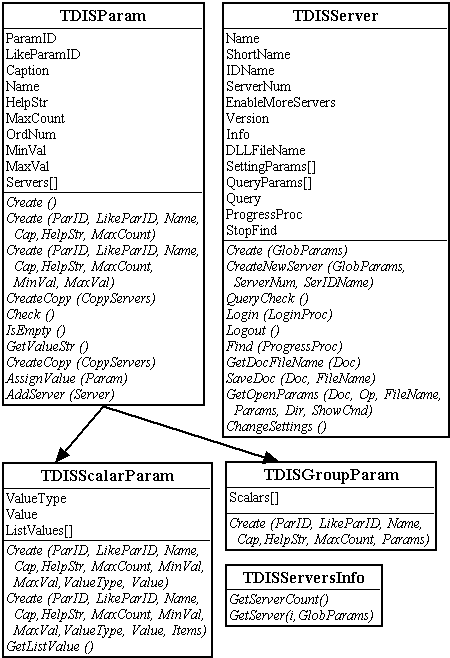
Pro specifikaci dotazů a také pro nastavení jednotlivých serverů bylo třeba vybudovat systém parametrů. Bylo několik alternativ, jak tento systém vytvořit:
Obecný systém - v jádře aplikace by byly nadefinované všechny možné parametry dotazu, které mají smysl. Při editaci by se uživateli tyto parametry zobrazily a on by je vyplnil. Tento seznam by pak dostaly všechny servery a ty by využily jen ty parametry, které samy podporují.
Nevýhody tohoto systému jsou zřejmé - málo flexibilní, moc omezené a dále nerozšiřitelné. Na jednu stranu by systém obsahoval zbytečné množství parametrů, které žádný server nevyužije (a uživatel by je tedy vyplňoval zcela zbytečně). Na stranu druhou by tento systém nebyl úplný - vždy by se našel server s parametrem, který tento systém neobsahuje.
Parametry definované v DLL knihovnách. Tento systém by byl velmi flexibilní, bylo by možné nadefinovat libovolný parametr. Nevýhodou je, že každá DLL knihovna bude zbytečně znovu definovat existující parametry.
V tomto případě jsou dvě možnosti, jak definovat seznam parametrů pro uživatele. První možností je udělat průnik parametrů, které nabízí uživatelem vybrané servery, druhou možností je vytvořit jejich sjednocení.
Nevýhodou je nejednoznačnost - dva servery můžou definovat jeden parametr, který defacto plní stejnou funkci, různě. Uživatel pak bude nucen tento parametr vyplňovat dvakrát.
Finální řešení - je založeno na využití kladných vlastností výše uvedených možností. Parametry budou definovány v DLL knihovnách, ale určitá množina nejčastějších a nejobecnějších parametrů bude definována mimo a bude volně využitelná všemi knihovnami.
Parametry budou jednoznačně identifikovány a tak nebude problém vytvořit rozumné sjednocení parametrů různých serverů bez ohledu na místo vytvoření parametru, bez toho aby se v tomto sjednocení objevily duplicity.
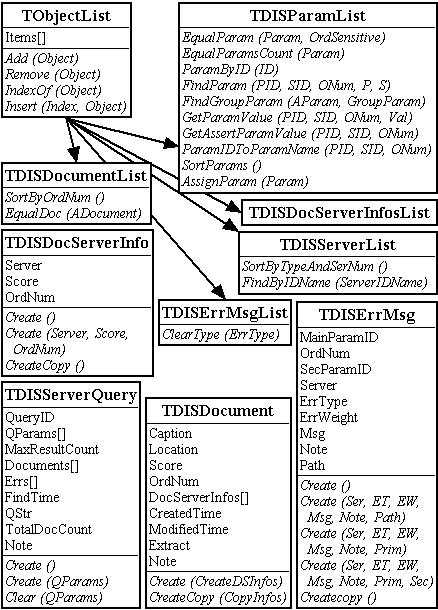
Základem je abstraktní objekt TDISParam, od něhož je odvozen objekt reprezentující parametr obsahující vlastní hodnotu (TDISScalarParam). Druhý odvozený objekt (TDISGroupParam) slouží k seskupení několika parametrů, popisujících stejnou vlastnost, do skupiny.
Mezi základní atributy objektu patří ParamID, který jednoznačně identifikuje parametr. LikeParamID se využívá při zatřídění parametru do seznamu při jeho vizuálním zobrazení. Caption, Name a HelpStr slouží k popsání významu vlastního parametru (nebo skupiny).
Některé parametry lze duplikovat. Jsou to ty, které mají MaxCount větší než nula. OrdNum uvádí číslo kopie parametru, originální (původní parametr, který byl duplikován) parametr má OrdNum = 1.
Pole serverů Servers obsahuje seznam serverů, které tento parametr podporují (pouze u parametrů na straně aplikace, na straně serveru je tento atribut nastaven na nil).
Tento potomek TParam obsahuje vlastní hodnotu. Ta je obsažena v řetězcovém atributu Value. Parametr může obsahovat hodnotu různého typu (ValueType):
- vtString, vtPassString
Řetězec, případně zašifrovaný řetězec (pro uložení hesla a jiných údajů, které se nesmí zobrazovat).
- vtBoolean
Pravdivostní hodnota. True je uloženo jako řetězec „1“ a False jako „0“.
- vtNumber, vtDecNumber
- vtDate
Datum, který je v řetězcovém atributu Value uložen jako řetězec reprezentující číslo s desetinnou čárkou (stejně jako typ TDateTime obsahuje toto číslo před desetinnou čárkou počet dní od roku 1899 a za čárkou část dne).
- vtList
Seznam, tedy výběr z předdefinovaných hodnot, které se nachází v poli ListValues. Vlastní hodnota obsahuje index vybraného prvku.
Obsahuje pole Scalars dále nedělitelných parametrů typu TDISScalarParam. Tyto parametry spolu souvisí, proto jsou uvedeny ve skupině (například jméno a heslo pro přihlášení na vzdálený server, nebo datumové rozpětí pro uložení poslední změny dokumentu).
Pro snazší vytváření parametrů obsahuje interface několik konstruktorů. Parametry mohou být vytvářeny kdekoliv. Některé parametry, které jsou nejběžnější (a tedy pro většinu serverů společné) jsou definovány ve zdrojovém souboru GlobalParams. Pole těchto globálních parametrů předává jádro aplikace jednotlivým serverům při jejich vytváření. Tyto servery si tak snadno mohou některé z nich přidat (vytvořit si svou kopii) do svého seznamu. Je tak zajištěna jistá jednoznačnost základních parametrů.
Další možností, kde vytvářet parametry, je vlastní server. Tady vznikl problém s vývojovým prostředím (Delphi 6 firmy Borland), neboť základní metoda objektu TObject:
function InheritsFrom(AClass: TClass): Boolean;
nepracovala správně.
V případě, že byla tato metoda volána v jiném procesu než byl objekt vytvořen (například pokud byl objekt vytvořen v DLL knihovně a pak se testoval jeho typ v aplikaci), vracela chybné výsledky. Řešením bylo zavedení balíčku obsahující vlastní rozhraní (DISIfacePackage.bpl), tedy definice všech objektů. Tento balíček musí být využíván jak aplikací, tak všemi DLL knihovnami (Obrázek 5.6.).
Cílem implementace bylo, aby systém parametrů umožňoval pro libovolný server zadat libovolný parametr, tedy aby bylo možné plně využití serveru. Na druhé straně byl měl ale zajistit uživatelskou přívětivost. Tedy rozhodně by neměl nutit uživatele vyplňovat pro každý server parametry, které jsou shodné (například termy, které musí/nesmí hledaný dokument obsahovat, jazyk dokumentu, …). Proto byla implementována metoda na slévání polí parametrů (GetCommonParams).
Výsledkem slévání je pole parametrů, které obsahuje všechny parametry všech zvolených serverů, ale pokud servery obsahují stejné parametry, jsou tyto ve výsledném seznamu uvedeny pouze jednou. Každý parametr v poli obsahuje seznam serverů (Servers), které daný parametr dodaly. Toto pole ukazatelů poté slouží ke zpětnému nastavení hodnot na stranu serverů - DLL knihoven (SetCommonParams).
Nejdůležitější je funkce, která rozhoduje o tom, zda dva parametry jsou si rovny (a tedy budou slity do jednoho):
function EqualParams (P1, P2: TDISParam;
OrdSensitive: Boolean): boolean;
P1 a P2 jsou porovnávané parametry,
OrdSensitive určuje, zda se má při porovnávání brát
v úvahu jejich atribut OrdNum.
Dva parametry jsou shodné, pokud:
Tato definice mimo jiné umožňuje, aby dvě různé DLL knihovny implementovaly shodné parametry bez toho, aby sdílely společný kód. Stačí, znát ParamID a typ parametrů, což lze snadno zjistit přímo v aplikaci.Pro práci s parametry bylo třeba vytvořit objekt, který by obsahoval více parametrů - k tomu je určen TDISParamList - potomek objektu Delphi TObjectList. Obdobně byly odvozeny objekty pro reprezentaci polí (seznamů) dalších používaných objektů (serverů, dotazů, dokumentů, chyb…): TDISServerList, TDISQueryList, TDISDocumentList, TDISErrorList, TDISDocServerInfosList, TDISQueryServerInfosList. A byly implementovány další potřebné metody pro vyhledávání, třídění a podobně.
Objekt TDISParamList obsahuje několik metod, které strojí za povšimnutí.
FindParam(PrimID, SecID, OrdNum: integer;
var Prim, Sec: TDISParam): boolean;
Slouží k hledání parametru daných vlastností (PrimID,
SecID, OrdNum).
PrimID obsahuje ID hledané skupiny, nebo skalárního parametru,
který není ve skupině.
SecID se použije pro hledání parametru ve skupině.
V takovém případě PrimID obsahuje ID skupiny a
SecID identifikátor skalárního parametru.
OrdNum udává pořadové číslo.
V Prim bude navrácen ukazatel na hledaný
skalární parametr (pokud není ve skupině), případně na skupinu.
Sec se použije v případě hledání skalárního parametru,
který se nachází ve skupině (ukazatel na skupinu bude v Prim).
GetParamValue (PrimID, SecID, OrdNum: integer;
var Val: string): boolean;
Pokusí se najít zadaný parametr a v proměnné Val vrátí
jeho hodnotu.
function EqualParam(AParam: TDISParam; OrdSensitive:
Boolean = true): TDISParam;
Nalezne první parametr shodný s AParam dle výše uvedené
definice v seznamu.
Ukázky několika parametrů
Parametr pro zadání slov, která má hledaný dokument obsahovat (nejběžnější parametr, který používá každý server).
TDISScalarParam.Create (
gpsidMainQueryAnd,
gpsidMainQueryAnd,
'Musí obsahovat',
'Musí obsahovat',
'Slova, která dokument musí obsahovat.',
1,
NotCheckVal,
NotCheckVal,
vtString,
''
);
Parametr pro zadání časového intervalu kdy byl dokument vytvořen, případně modifikován. Jelikož musí parametr obsahovat dva časové údaje, nejedná se o jeden skalární parametr, ale o skupinu parametrů, jež obsahuje dva skaláry, které je nejprve třeba vytvořit.
Scal1 := TDISScalarParam.Create (
gpsidDocDate_From,
gpsidDocDate_From,
'Datum od',
'Od',
'Počátek intervalu, kdy byl dokument vytvořen (modifikován)',
1,
NotCheckVal,
NotCheckVal,
vtDate,
''
);
Scal2 := TDISScalarParam.Create (
gpsidDocDate_To,
gpsidDocDate_To,
'Datum do',
'Do',
'Konec intervalu, kdy byl dokument vytvořen (modifikován)',
1,
NotCheckVal,
NotCheckVal,
vtDate,
''
);
TDISScalarGroup.Create (
gpgidDocDate,
gpgidDocDate,
'Datum dokumentu',
'Datum modifikace dokumentu',
'Časový interval, kdy byl dokument vytvořen (modifikován)',
1,
[Scal1, Scal2]
);
DLL knihovna jež implementuje DIS server, musí exportovat funkci bez parametrů, vracející potomka objektu TDISServersInfo. Tento objekt (TDISServersInfo) slouží ke zjištění počtu serverů, které tato knihovna implementuje (metoda GetServerCount ()) a také k jejich vytvoření metodou GetServer (i, GlobParams), kde i je index vytvářeného serveru a GlobParams je pole základních nejčastěji používaných parametrů, které server může využít (implementovat).
Z výše uvedeného vyplývá, že jedna DLL knihovna může obsahovat několik serverů, což je velmi výhodné. Obvzláště v okamžiku, kdy jsou tyto servery velmi podobné a mohou se tak snadno odvodit od společného předka (jak to bylo provedeno v případě implementace webových fulltextových vyhledávačů).
Vlastní server je v DLL knihovně implementován potomkem objektu TDISServer. Objekt obsahuje jednoduché atributy popisující server: jméno (Name), jeho zkratku používanou ve stručnějších výpisech (ShortName), číslo verze (Version) a další informace (Info).
Pro vlastní nastavení serveru slouží pole parametrů SettingParams. Obdobné pole QueryParams slouží k uchování parametrů dotazu, jež server poskytuje. Při vlastním vyhodnocení dotazu se používá instance objektu TDISServerQuery. Průběh vlastního vyhledávání se zobrazuje pomocí feedbackové funkce ProgressProc. Pokud si uživatel přeje zastavit vyhledávání, nastaví se atribut StopFind na True.
Někdy je potřeba používat několik serverů stejného typu. Například v případě dat uložených na několika serverech Oracle8i interMedia. Toto je řešené vytvořením více kopií serverů, které se budou lišit v nastavení (budou mít různé adresy, jména, hesla, …) a také v některých parametrech dotazu. O tom, zda server podporuje vytváření dalších kopií rozhoduje jeho vlastnost EnableMoreServers. Tyto kopie se pak liší ve svém pořadovém čísle (ServerNum). Pro jednoznačnou identifikaci serveru slouží atribut IDName.
Z metod stojí za zmínku Login a Logout pro připojení a odpojení od skutečného DIS serveru, QueryCheck pro otestování položeného dotazu, a Find pro vlastní hledání.
Po získání seznamu dokumentů odpovídajících dotazu by měl sever umět stáhnout dokumenty na lokální disk a zobrazit je. Slouží k tomu metody GetDocFileName (zjištění jména dokumentu z objektu TDISDocument), SaveDoc (získání dokumentu a jeho uložení na disk) a GetOpenParams (nastavení parametrů pro jeho zobrazení v asociované aplikaci funkcí ShellExecute).

Jádro aplikace (DISEngine) při přihlášení uživatele vytvoří seznam dostupných DLL knihoven (tyto se musí nacházet v podadresáři Servers). Jedna knihovna může obsahovat i několik různých serverů, jejich počet a jednotlivé instance se získá přes potomka objektu TDISServersInfo (viz oddíl nazvaný „Struktura DLL knihovny“). Některé servery mohou mít navíc další kopie (viz oddíl nazvaný „Vlastní server“).
Z těchto serverů se získá jejich pole nastavovacích parametrů (SettingParams), ze kterých se poskládá globální seznam parametrů nastavení všech serverů. Tento seznam neobsahuje žádné hodnoty. Ze sekce Global/ServersSetting ini souboru uživatele (User.ini) se načtou všechny dříve uložené hodnoty tohoto seznamu. Nastavené parametry se překopírují do lokálních polí příslušných serverů. Nyní je aplikace připravena pro vyhodnocování uživatelových dotazů.
Pro vytvoření prázdného dotazu je nutno zavolat metodu CreateNewQuery objektu TDISEngine. Prvním parametrem je identifikátor dotazu, ze kterého se odvozuje (odvození slouží k překopírování hodnot z původního dotazu, dojde vlastně k vytvoření kopie dotazu), případně nil, pokud se jedná o zcela nový dotaz.
Druhým parametrem je seznam serverů, které má dotaz využít. Tyto servery se překopírují do příslušného seznamu QServers v nově vytvořeném objektu TDISQuery. Posledním krokem vytvoření nového dotazu je získání seznamu parametrů. Ten se získá zavoláním metody GetCommonParams.
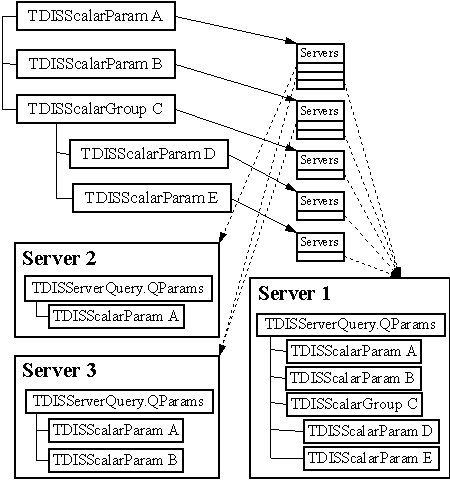
Nyní je na uživateli, aby vyplnil vlastnosti a další parametry dotazu. Při tom má stále možnost přidávat (TDISQuery.AddServer) a ubírat (TDISQuery.RemoveServer) servery, kterých se bude dotaz týkat. Po každé takovéto změně je třeba přidat do seznamu nové parametry, či naopak odstranit ty přebytečné. Tady je ještě nutno poznamenat, že při přidávání serveru je nejdříve nutné se na tento server připojit voláním jeho metody Login. U některých serverů, kde není potřeba se přihlásit (například webové vyhledávače), je tato metoda prázdná. Pokud je volání neúspěšné, server nebude přidán.
Po ukončení editace se zkontrolují uživatelem zadané údaje metodou TDISEngine.QueryCheck. Jelikož je kontrola parametrů závislá na zvolených serverech, vyplní tato metoda serverové objekty Query parametry dotazu (SetCommonParams) a poté zavolá QueryCheck jednotlivých serverů a získá pole případných chyb (TDISErrMsgList), které zobrazí uživateli.
Vlastní vyhledávání je poměrně jednoduché. Nastaví se parametry dotazu na straně serveru (objekt Query typu TDISServerQuery) a pro každý server se vytvoří hledací vlákno (TDISFindThread) s parametry: pořadí serveru, zpětně volaná funkce pro zobrazení postupu hledání GProgressProc, další zpětně volaná funkce, která se volá při skončení vyhledávání EndThreadProc a odkaz na příslušný server. Hledací vlákno okamžitě po svém vytvoření začne vyhledávat, což spočívá v zavolání metody Find přiděleného serveru a předání funkce na zobrazování průběhu. Při ukončení aktivity vlákna (vyhledávání) se zavolá metoda EndThreadProc. Průběh hledání lze také předčasně ukončit nastavením atributu StopFind = True serveru.
Po ukončení hledání server připraví pole nalezených dokumentů (ne vždy je to tak triviální - viz oddíl nazvaný „Implementace webových vyhledávačů“). Pokud cílový DIS server podporuje ohodnocení, musí být toto ohodnocení převedeno do intervalu 0..100.
Jakmile všechny servery (vlákna) ukončily vyhledávání přichází na řadu další fáze - získání výsledků. Metoda GetQueryResults projde všechny oslovené servery a vytvoří si informační objekt typu TDISQueryServerInfo, který popisuje výsledek vyhledávání daného serveru (počet nalezených dokumentů, počet vrácených dokumentů, počet chyb, dotazovací řetězec, dobu trvání vyhodnocení dotazu a další).
Vrátí-li server nějaké dokumenty, přidá je do seznamu všech nalezených dokumentů. Ale nejdříve zjistí, zda už daný dokument není v seznamu obsažen (pomocí metody TDISDocumentList.EqualDoc). Je-li již v seznamu, spojí dokumenty do jednoho. Tedy přepočítá výsledné skóre a pořadí dokumentu a do pole DocServerInfos dokumentu přidá odkaz na další server.
Není-li v seznamu ještě obsažen, přidá jej tam a do pole DocServerInfos dokumentu vloží odkaz na informující objekt TDISDocServerInfo (kde je uveden odkaz na server, skóre a pořadí dosažené na tomto serveru).
Zde nastal problém se způsobem uspořádávání dokumnetů na výstupu. Jelikož ne každý server vrací ohodnocení dokumentu (míru jeho relevantnosti vzhledem k položenému dotazu), nelze použít skóre (jak by se potom měly zařadit neohodonocené dokumenty?). Jedním z možných řešení (které bylo nakonec použito) bylo využití pořadí dokumentu, které vrací každý server. V přehledu nalezených dokumentů tak přibyl další sloupeček informující o celkovém pořadí. Toto Výsledné pořadí (a stejně tak skóre) se vypočte jako aritmetický průměr pořadí (skóre) dosažených na jednotlivých serverech. Způsob, jak tento problém řeší ostatní metavyhledávače, se bohužel nepodařilo zjistit (jejich výrobci odmítli podat bližší popis z důvodu utajení těchto algoritmů před konkurencí).
Pro zobrazování dokumentů bylo uvažováno o několika alternativách:
Zobrazení pomocí externího webového prohlížeče - nešlo by prohlížet dokumenty jiného typu než HTML stránky (snad jen ještě některé další formáty v závislosti na pluginech nainstalovaných do prohlížeče).
Implementace vlastního prohlížeče v DLL knihovně - zbytečně složité, málo flexibilní. Navíc v případě, že místo grafického rozhraní by byl modul chovající se jako webová služba, by byl tento prohlížeč naprosto zbytečný.
Zavolání externího prohlížeče, který je asociován s koncovkou příslušného dokumentu - tato možnost se nakonec ukázala jako optimální. DLL knihovna serveru, který daný dokument nalezl rozhoduje o jeho koncovce a také specifikuje parametry funkce ShellExecute, která dokument zobrazí. Není proto složité dodat zároveň s DLL knihovnou externí prohlížeč, který se bude volat.
Další problém vznikl při řešení zobrazení seznamu parametrů uživateli. Původně se uvažovalo o jednoduchém Layout manageru, který by řídil rozmístění vstupních polí pro jednotlivé parametry v dialogu. Toto se záhy ukázalo jako velmi složité a nepřehledné, protože výsledný seznam může obsahovat až několik desítek parametrů (plus další nově vytvořené kopie).
V konečném řešení (Obrázek 5.9.) jsou parametry reprezentovány jednoduchým stromem, který obsahuje maximálně dvě úrovně - vlastní parametr (TDISScalarParam) a případně skupina (TDISGroupParam), která parametr obsahuje. Komponenty pro zadání dat skupiny parametrů jsou v dialogu umístěny jednoduše pod sebou.
Toto řešení je velmi přehledné a elegantní. Hodnoty nastavených parametrů lze vidět přímo ve stromě a dialog není přeplácaný díky tomu, že se zobrazuje pouze vstupní pole vybraného parametru (případně několik komponent, pokud je parametr součástí skupiny).
Uživatelské prostředí aplikace neobsahuje mnoho dalších zajímavých technik. O možnostech, které uživateli nabízí pojednává spíše uživatelská část dokumentace. Jedinými zajímavými oblastmi je export seznamu dokumentů a formát ukládání dat (nastavení aplikace).
Seznam nalezených dokumentů, který aplikace po vyhledání zobrazí je možné uložit do souboru a později znovu načíst. Další možností uchování těchto dat je export. V současné době jsou podporovány tyto formáty:
- HTML dokument (html)
Výpis vygenerovaný jako HTML stránka s použitím kaskádových stylů.
- Comma Separated Value (csv)
Tento formát lze načíst do většiny tabulkových programů jako je například Microsoft Excel (kde lze s daty dále pracovat). Jednotlivé hodnoty jsou ve výstupním souboru odděleny čárkou, věty jsou odděleny odřádkováním.
- Čistý text (txt)
Univerzální formát. Neobsahuje žádné formátovací tagy, výstup lze prohlížet na libovolné platformě.
Šablonu exportu tvoří jednoduchý textový soubor, který kromě vlastního formátování výstupního exportu (například HTML tagy v případě HTML exportu) obsahuje i speciální tagy, které aplikace nahradí příslušnými daty. Tyto tagy mají následující syntaxi:
<#JMENO_TAGU JMENO_ATRIBUTU='HODNOTA'>
Jména možných tagů i s vysvětlivkami viz 5.1..
Tabulka 5.1. Názvy a popisy tagů šablony
| Název tagu | Význam |
|---|---|
| ACT_DATE | Aktuální datum a čas (tedy datum a čas exportu) |
| USER_NAME | Jméno aktuálně přihlášeného uživatele |
| DOC_COUNT | Počet nalezených dokumentů |
| Tagy reprezentující vlastnosti dotazu | |
| QNAME | Název dotazu |
| QCREATED | Datum a čas vytvoření dotazu |
| QEDITED | Datum a čas poslední modifikace dotazu |
| QSEARCHED | Datum a čas posledního vyhledávání dokumentů odpovídajících dotazu |
| QTOTAL_COUNT | Maximální počet nalezených dokumentů z jednoho serveru |
| QSERVER_COUNT | Počet dotazem využívaných serverů |
| QSERVERS | Seznam serverů, které dotaz používá pro vyhledávání |
| QNOTE | Poznámka k dotazu |
| Tagy reprezentující vlastnosti dokumentu | |
| DNUM | Aktuální číslo dokumentu |
| DNAME | Název dokumentu |
| DLOCATION | Lokace dokumentu |
| DSCORE | Celkové skóre dosažené dokumentem |
| DORDNUM | Celkové pořadí dokumentu |
| DCREATED | Datum vytvoření dokumentu |
| DMODIFIED | Datum poslední změny dokumentu |
| DEXTRACT | Ukázka z dokumentu |
| DNOTE | Poznámka k dokumentu |
| DSERVERINFOS | Informace o hodnocení dokumentu servery, které jej nalezly |
| Speciální tagy | |
| TEMPLATE_INFO | Tag popisující vlastní šablonu, musí být uveden na začátku souboru (tedy jako první tag), má dva atributy viz popis dále. |
| LIST_BEGIN | Tag označující začátek smyčky, která obsahuje všechny nalezené dokumenty. Mezi tagy LIST_BEGIN a LIST_END by měly být uvedeny tagy popisující dokument, které budou nahrazeny skutečnými vlastnostmi nalezených dokumentů. |
| LIST_END | Konec smyčky dokumentů |
Rozšiřující atributy jsou použity pouze u jediného tagu TEMPLATE_INFO, který popisuje šablonu a musí být uveden na samém začátku souboru.
popis jeho atributů:
- Ext
Koncovka, s jakou se bude soubor ukládat (html, txt, xml, …). Tato koncovka je poměrně důležitá, neboť to bude výchozí koncovka, pokud uživatel nezapíše jinou. Také určuje který prohlížeč se použije pro zobrazení výsledného exportu (dle nastavení asociací v systému).
- Name
Jméno (může být i s krátkým komentářem), pod jakým bude šablona uvedena v seznamu dostupných formátů pro export.
Pro čitelné ukládání nastavení aplikace, historie dotazů a seznamů nalezených dokumentů bylo rozhodnuto používat nějakou formu textového souboru. Třída TIniFile implementovaná ve vývojovém prostředí Delphi od jeho první verze se záhy ukázala jako nedostatečná z několika důvodů:
TSetFile umožňuje načítat a ukládat proměnné typu Integer, Boolean, Extended, TDateTime a String (pro řetězec je určena ještě jedna metoda na ukládání „dlouhého“ řetězce, který může obsahovat odřádkování)
Veškerá data souboru se načtou metodou Load do paměti, konkrétně do objektu TStringList, kde se jednotlivé řádky převedou na vnitřní strukturu, která je optimálnější pro další práci. To spočívá mimo jiné ve zrušení uvozujících mezer a vypuštění přebytečných dat (prázdné řádky a komentáře). V každém řádku vnitřní struktury je na začátku uvedeno jméno hlavní sekce a podsekce, poté následuje jméno atributu a vlastní hodnota.
Příklad převodu dat na vnitřní strukturu:
Data v uloženém souboru:
; -------------------------------
; Toto je INI soubor uzivatele
; -------------------------------
[[Application]]
[Window]
Left=50
Top=62
Width=923
Height=644
[[Global]]
[DuplServers]
ServerCount=1
ServerClass0=TDISOracleServer
Data ve vnitřní struktuře:
[Application][Window]
[Application][Window]Left=50
[Application][Window]Top=62
[Application][Window]Width=923
[Application][Window]Height=644
[Global][DuplServers]ServerCount=1
[Global][DuplServers]ServerClass0=TDISOracleServer
Jelikož se tento formát používá převážně pro ukládání nastavení, je vysoce pravděpodobné, že data se budou číst v tom pořadí, jak jsou uložená. Proto zde byla zavedena optimalizace spočívající v zapamatování poslední pozice, kde se četla data. Při dalším požadavku se data hledají od této pozice dále a teprve v případě neúspěchu se začne hledat od začátku.
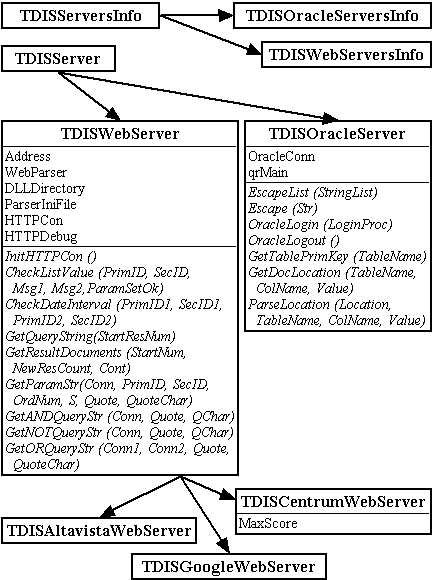
Pro implementaci webových fulltextových vyhledávačů byl vytvořen objekt TDISWebServer, ze kterého se odvozují objekty pro konkrétní servery (TDISAltavistaWebServer, TDISCentrumWebServer, TDISGoogleWebServer).
Hlavním úkolem tohoto objektu je komunikace s příslušným WWW serverem přes protokol HTTP (HyperText Transfer Protocol). Tuto komunikaci zajišťují komponenty TIdHTTP a TIdLogDebug vývojového nástroje Delphi 6.
Jelikož TDISWebServer je jen meziobjekt, nechává většinu důležitých metod prázdnou, implementuje pouze společnou část pro všechny webové vyhledávače:
Ostatní metody musí být implementovány až u jednotlivých potomků:
Při využívání webových fulltextových vyhledávačů vznikl problém, jak získat informace, které jsou obsaženy v odpovědní stránce mezi dalším balastem, jež tato stránka obsahuje. Problém byl vyřešen textovým parserem TTextParser s externím konfiguračním souborem, který umožňuje snadno a pružně reagovat na změnu struktury stránky s výsledky (postačí změnit několik řetězců).
Vlastní objekt TTextParser obsahuje pole objektů typu TTokenGroup. Každá skupina (TTokenGroup) se skládá z několika (samozřejmě může obsahovat i jen jeden samotný token) tokenů (TToken). Token je nejmenší jednotka, představující hledanou informaci v textovém řetězci. Skládá se z těchto položek (Obrázek 5.11.):
- Name
Jméno (identifikátor) tokenu, důležité při zavěrečném získávání dat z parseru.
- Value
Vlastní hodnota (údaj, který je třeba získat ze vstupního řetězce).
- Mandatory
Povinnost tokenu, využije se při parsovaní celé skupiny. Jestliže skupina po naparsování nezískala hodnotu tokenu, který má nastaven Mandatory=True, pak celá skupina při získávání dat selhala.
- StartTag
Řetězec, který uvozuje vlastní hodnotu Value, tedy řetězec ve vstupním textu, za kterým následují důležitá data, která je třeba získat.
- EndTag
Opak StartTagu - řetězec, který se nachází za důležitými daty a označuje tak jejich konec.
- StopTag
Pokud se při parsování textu za vlastními daty nenalezne EndTag, obsahoval by token nesmyslná data. Případně by se EndTag mohl najít někde dále v těle dokumentu. StopTag slouží k vymezení oblasti hledání EndTagu. Pokud na něj Parser narazí (při načítání dat, tedy až poté co našel StartTag), znamená to, že hodnota tokenu nebyla nalezena.

Příklad tokenu pro získání počtu Altavistou nalezených stránek:
TokenName="TotalFound"
StartTag="Inclusion\">We found "
EndTag=" results:</b></a><br>"
StopTag="<br>"
Skupina Tokenů (TTokenGroup) je určena pro načítání množiny dat, která se několikrát v textu opakuje. Stránka, kterou vrátí webový vyhledávač, obsahuje několik jedinečných údajů (například počet všech stránek odpovídajících položenému dotazu) a dále množinu údajů, jejichž struktura se několikrát opakuje (například informace o nalezených stránkách - název, adresa, dosažené skóre, ukázka textu, datum). Některé požadované údaje z této množiny jsou nezbytné (URL stránky), jiné jsou nepovinné (ukázka, datum a podobně). Pokud je třeba naparsovat jedinečný údaj (tento je samozřejmě definován pomocí jednoho tokenu), je pro snazší a jednotnou manipulaci použita skupina obsahující tento jediný token.
Atribut ValueParsed skupiny určuje, zda se povedlo při parsování načíst hodnotu. Tedy zda se načetly hodnoty pro všechny její tokeny s atributem Mandatory = True.
RepeatCount udává kolikrát se tato skupina tokenů v parsovaném textu opakuje (a tedy kolikrát po sobě se budou její hodnoty načítat). Defaultně je RepeatCount=0, což znamená, že se skupina nebude opakovaně načítat.
S RepeatCount souvisí další atribut SeqNum, který určuje, o kolikátou instanci množiny jde.
Hlavní a nejdůležitější metodou je
Parse (S: string; StartPos: integer): integer;která projíždí řetězec S od pozice StartPos a snaží se v něm najít hranice a obsah tokenů skupiny. K tomu využívá jednodušší metodu
FindToken(S: string; var T: PToken; Start: integer): integer;pro vyhledání tokenů skupiny.
Postup je jednoduchý - projíždí pole tokenů a hledá je v zadaném textu. Uspěje-li, pří hledání tokenu metodou FindToken, pokračuje hledáním dalšího od pozice, kterou tato metoda vrátila. Neuspěje-li, hledá další token od stejné pozice (pokud nenalezený token nebyl povinný), nebo skončí s nezdarem (byl-li hledaný token povinný).
Objekt TParser obsahuje pole skupin. Definice těchto skupin je buď obsažena přímo v kódu a vytvoří se pomocí příslušných pomocných metod (Add, AddGroup, InsertGroup) a nebo se jejich struktura načte z textového souboru.
V souboru lze používat řádkové komentáře (veškerý text za znakem „%“), pro větší přehlednost mohou být jednotlivé řádky indentovány a prokládány prázdnými řádky. Každý jednotlivý údaj musí být zapsán na samostatném řádku. Hodnoty tagů (TOKENNAME, STARTTAG, ENDTAG, STOPTAG) nesmí volně obsahovat znak „"“ (uvozovky), byl by totiž chápán jako konec řetězce. Proto musí být escapován (uvozen znakem „\“). Stejně tak musí být ošetřen i samotný znak „\“. Má-li tedy tag obsahovat „\“, musí to být zapsáno takto: „\\“.
Jelikož formát HTML není citlivý na počet mezer či odřádkování ve zdrojovém textu stránky, není třeba tyto znaky (dokonce je zakázáno zapsat do tagu odřádkování, mezery jsou povoleny) do obsahu tagu zapisovat. Při porovnávání jsou veškeré bílé znaky (mezery, odřádkování, tabulátor) ve vstupním textu i v tagu ignorovány.
Soubor obsahuje následující klíčová slova:
Příklad ini souboru pro parser Altavisty:
;-------------------------------------------
; ParserSettings pro Altavistu
; Petr Vaclavek 4. 11. 2001
;-------------------------------------------
TOKEN_BEG
TokenName="Hledane slovo"
StartTag="- Web Results for: "
EndTag="</title>"
Mandatory=0
TOKEN_END
; Celkovy pocet nalezenych stranek
TOKEN_BEG
TokenName="TotalFound" % znak " je escapovan
StartTag="Inclusion\">We found "
EndTag=" results:</b></a><br>"
Mandatory=1
TOKEN_END
; Jednotlive stranky a informace o nich
GROUP_BEG
RepeatCount=1000
TOKEN_BEG
TokenName="DocURL"
StartTag="onMouseOver=\"status='"
EndTag="'; return"
Mandatory=1
TOKEN_END
TOKEN_BEG
TokenName="DocName"
StartTag="true;\">"
EndTag="</a>"
Mandatory=0
TOKEN_END
TOKEN_BEG
TokenName="DocExtract"
StartTag="<br>"
EndTag="<br><span"
StopTag="<span"
Mandatory=0
TOKEN_END
GROUP_END
Po vytvoření pole skupin (ať už pomocí volání metod nebo načtením struktury ze souboru) je třeba naparsovat vstupní text. K tomu je určena hlavní metoda objektu TTextParser:
ParseText (S: string): boolean;Tato metoda prochází polem skupin a pokouší se je naparsovat. Uspěje-li a má-li se skupina opakovat (atribut RepeatCount > 1), vytvoří její kopii s nižším RepeatCount a vyšším pořadovým číslem SeqNum a opět se ji pokusí naparsovat. Neuspěje-li, přejde na následující skupinu.
Ke zjištění naparsovaných hodnot slouží metoda
GetTokenValue (TokName: string; SNum: integer;
var Val: string): TTokenState;
Hledaná hodnota je identifikována názvem tokenu a pořadovým číslem skupiny.
Návratová hodnota metody udává, zda byl token nalezen a naparsován, či nikoliv.
Před dalším parsováním je třeba odstranit kopie opakovaných skupin, jež byly vytvořené minulým prohledáváním. K tomu je určena metoda ClearTokens.
DLL knihovna implementující Oracle8i interMedia je jediná knihovna jež využívá možnosti vytvářet více kopií tohoto serveru. Díky tomu umožňuje uživateli paralelně vyhledávat stejný dotaz na několika Oracle serverech.
Parametry ve kterých se tyto instance odlišují se týkají zejména nastavení (zdroj dat, jméno, heslo, název serveru) a také dotazu (jméno tabulky, ve které se bude hledat, mapování sloupců a další podmínky na atributy tabulky). Každý nově vytvořený server musí mít jiné (jednoznačné) ID těchto parametrů, proto se při vytváření serveru využije informace o čísle instance serveru (ServerNum) a původní ID parametru se posune o příslušnou konstantu. Navíc jsou jednotlivé servery jednoznačně identifikovány pomocí IDName.
Komunikaci mezi DLL knihovnou a vlastním Oracle serverem zajišťují komponenty TADOConnection a TADOQuery.
Na rozdíl od ostatních implementovaných serverů se v tomto případě plně využívá metoda Login. Slouží nejen k vlastnímu připojení k serveru (pomocí TADOConnection), ale také k získání důležitých informací o datech zde uložených. Konkrétně se jedná o získání seznamu použitelných tabulek, nad kterými byl vytvořen textový index. K těmto tabulkám ještě zjistí seznam jejich atributů. Všechny tyto údaje vyplní do příslušných parametrů dotazu.
Vlastní vyhledávání spočívá ve vytvoření klasického SQL dotazu, který je zaslán na server a zpracování množiny záznamů odpovídajících dotazu. Dokumenty (texty, které jsou prohledávány) musí být obsaženy v tabulkách, nad kterými jsou vytvořeny textové indexy. Navíc je v aplikaci podporován pouze jeden způsob uložení textových dat a to přímo ve sloupečku tabulky (jiné tabulky se v parametru pro výběr zdroje dat ani neobjeví). To znamená, že při vytváření textového indexu nad tabulkou byl nastaven parametr DATASTORE na DIRECT_DATASTORE. Další informace o Oracle8i interMedia viz 11.
Jelikož DISClient využívá pro vlastní hledání dokumentů na Internetu fulltextové vyhledávače, měl by uživateli nabídnout stejné možnosti. To se týče jednak parametrů dotazu a jednak možností prostředí. Parametry lze snadno díky zavedenému systému implementovat. S prostředím je to horší, neboť běžný uživatel je zvyklý na používání oblíbeného internetového prohlížeče nejen pro vyhledávání ale také pro prohlížení nalezených dokumentů. Je pro něj tedy nezvyklé zadávat dotazy v jedné aplikaci a výsledky si prohlížet v druhé.
Jednou z možností jak alespoň částečně simulovat uživateli prostředí na jaké je zvyklý, je zapnutí automatického exportu (Nastavení/Export/Automaticky zobrazovat). Výsledky se po ukončení vyhledávání exportují do zvoleného formátu (např. HTML stránky) a zobrazí se v nastaveném prohlížeči, kde si je může uživatel libovolně prohlížet a procházet mezi nimi.
Jinou možností je implementace dalšího modulu využívající jádro aplikace (DISEngine). Aplikace by se pak chovala jako další internetový metavyhledávač (viz oddíl nazvaný „Vývoj architektury“ a Obrázek 5.2.).
Program však přináší spoustu dalších výhod a možností: ukládá historii dotazů, takže se k nim může uživatel kdykoliv vrátit, znovu vyhledat, či přímo stáhnout dokument z dříve uloženého seznamu. Po vyhledání lze s výsledky dále pracovat - uložit seznam, třídit dle různých kritérií či vyexportovat do libovolného (i vlastního) textového formátu
Navíc uživatel může paralelně vyhledávat v několika zdrojích dat (i když to webové metavyhledávače umožňují také) a tyto zdroje nemusí být pouze fulltexty na Internetu (to už dostupné metavyhledávače neumí). Díky paralelnímu zpracování je vyhledávání podstatně rychlejší, než postupné ruční vyhledávání na jednotlivých serverech.
Ve srovnání s dostupnými desktopovými vyhledávači (viz Kapitola 4., Obdobné aplikace) patří mezi základní přínosy zastoupení českých vyhledávačů, cena (jedná se o volně šiřitelný program), dostupnost zdrojových kódů a hlavně rozšiřitelnost. Kdokoliv může vytvořit novou knihovnu pro vyhledávání nejen pomocí dalších webových služeb, ale i pro jakékoliv jiné zdroje dat (soubory na disku, data emailových klientů, data v databázích, knihovní systémy, …). Navíc uživatel smí plně využívat možnosti, které nabízí jednotlivé vyhledávací servery, ovlivnit způsob exportu výsledků a podobně.
Na druhou stranu ale DISClient nedisponuje některými funkcemi, které uvedené aplikace obsahují: integrace do systému, prohlížeče, vlastní prohlížeč s vestavěnými vylepšeními (např. zvýraznění hledaných slov), agenti na automatické vyhledávání nových dokumentů odpovídajících dotazu, kontrola dokumentu (dosažitelnost, vlastní explicitní kontrola zda opravdu vyhovuje dotazu, …) a další. Ovšem není problém výše uvedené chybějící vlastnosti do aplikace doprogramovat.
Aplikaci lze samozřejmě dále vyvíjet a vytvořit tak plnohodnotný produkt dosahující (a v mnohých ohledech přesahující) možnosti komerčních aplikací.
Hlavní možnosti rozšíření aplikace:
Vytvoření nových DLL knihoven pro další servery:
Další webové fulltextové vyhledávače (atlas, excite, msn, …).
Jiné webové služby, například hledání v diskusních skupinách: Google Groups (http://www.google.com/grphp), Serge (http://www.serge.cz), vyhledávání ve slovnících, encyklopediích: Britannica (http://www.britannica.com), …
Vyhledávání dokumentů v dalších databázích (MS SQL, Interbase, Sybase, Informix, …).
Úplně nové oblasti - fulltextové prohledávání souborů na lokálním disku, korespondence v emailových klientech, …
Vylepšení stávajících DLL knihoven: přidání dalších parametrů zejména pro Oracle8i interMedia (například zapojení tezauru, prohledávání v datech, které nejsou uloženy přímo ve sloupečku tabulky), využití koláčků (cookie) pro nastavení webových vyhledávačů (hlavním přínosem by bylo získání více informací o nalezených dokumentech, neboť tyto vlastnosti je třeba nastavit právě pomocí cookie).
Místo GUI vytvořit jiný modul, jenž by využíval hledacího jádra aplikace (DISEngine) viz Obrázek 5.2..
Mnoho dalších drobných vylepšení uživatelského prostředí, kterými disponují konkurenční produkty (zejména jejich placené „Plus“ a „Pro“ verze).
Výsledkem diplomové práce nazvané „Klient DIS“ je plnohodnotná aplikace, která umožňuje uživateli vyhledávat v několika různorodých datových zdrojích.
Velkou výhodou je skutečnost, že ačkoliv je program hotový, lze jej dále rozšiřovat co do rozsahu implementovaných funkcí v jednotlivých knihovnách DLL tak do množství dalších knihoven, které si díky univerzálnímu rozhraní může každý vývojář napsat sám. Dlaším velkým plusem je oddělení vlastního jádra od uživatelského prostředí, není proto problém vytvořit zcela jinou aplikaci (službu) využívající toto „multivyhledávací“ jádro.
Jeden z hlavních přínosů je řešení systému parametrů, který umožňuje vývojářům implementovat téměř libovolný parametr dotazu nového DIS Serveru. Navíc bylo poměrně elegantně vyřešeno zobrazení těchto parametrů uživateli.
Při vývoji byla snaha pokrýt všechny nedostatky zjištěné u obdobných nástrojů, kterými byl vývoj vlastní aplikace značně inspirován.
DISClient je nástroj sloužící pro snadné fulltextové vyhledávání nejen pomocí známých webových vyhledávačů jako je například Altavista, Google a podobně, ale umožňuje také přidávat další zdroje dat, které mohou obsahovat hledané dokumenty (například data uložená na Oracle8i interMedia).
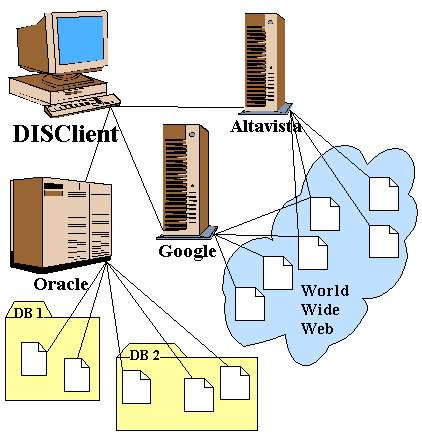
Hlavní výhodou tohoto systému je počet oslovených serverů a přívětivé prostředí, ve kterém si uživatel definuje svůj dotaz. Nemusí se tak učit speciality jednotlivých vyhledávacích serverů, nemusí znát syntaxi na nich pokládaných dotazů. Práce je tak podstatně snazší, rychlejší a efektivnější.
Další výhodou je možnost nastavení prostředí, přednastavitelné speciální funkce jako je například rychlé hledání, či export. Nezanedbatelné je také uchovávání historie hledání a možnost uložení a exportu výsledků. Kdykoliv se tak může uživatel vrátit ke staršímu dotazu a znovu vyhledat odpovídající dokumenty nebo jen načíst informace o dříve nalezených dokumentech.
Díky tomu, že aplikace využívá více zdrojů dat, zpracuje podstatně více (a kvalitněji) jejich výsledky než by to provedl samotný uživatel postupným použitím jednotlivých serverů. Aplikace tyto servery oslovuje paralelně a navíc automaticky filtruje duplicity a umožňuje uspořádávat nalezené dokumenty.
Veškerý popis práce s aplikací DISClient je náplní tohoto manuálu. Pro pochopení je potřeba znát základní pojmy a mít jisté znalosti při práci v prostředí Microsoft Windows.
V případě používání knihovny pro Oracle je potřeba mít nakonfigurován ODBC ovladač pro Oracle 8, odpovídajícího klienta (ten je součástí klientské instalace Oracle) a podpora ADO (Microsoft ActiveX Data Objects) verze 2.1 (nebo vyšší). Ta je již součástí operačních systémů Microsoft Windows 2000 a XP. Pro jiné systémy ji lze zdarma stáhnout na stránkách Microsoftu (http://www.microsoft.com)
Aplikace byla koncipována tak, aby běžela na operačním systému Windows 2000 hlavně z důvodu chyb v dřívějších operačních systémech. Zejména se jedná o velmi časté chyby, jež obsahuje knihovna comctrl32.dll, kterými trpí zejména produkty vytvořené v Delphi či C++ Builderu.
V žádném případě tím ale není řečeno, že by produkt na jiné platformě než Windows 2000 neběžel, ale pouze to, že tam nemusí pracovat tak, jak bylo zamýšleno právě díky výše zmíněným problémům.
Instalace aplikace DIS Client je velice jednoduchá a probíhá v několika málo krocích. Lze ji kdykoliv zastavit tlačítkem Zrušit. Uživatel pak bude dotázán, zda opravdu chce instalaci ukončit. K dokončení se pak může kdykoliv vrátit.
Prvním krokem je spuštění instalačního souboru DISClient.msi. Po inicializaci se objeví přivítací dialog (Obrázek A.2.).

Po stisku tlačítka Další se zobrazí dialog pro zadání lokace na disku, kam se má aplikace nainstlaovat (Obrázek A.3.). Změna cílového adresáře se provede za pomoci tlačítka Procházet.

Nyní je instalátor připraven nainstalovat DIS Client na uživatelův disk. (Obrázek A.4.). To spočívá v nakopírování souborů do zadaného adresáře, vytvoření zástupce v nabídce Start a přidání programu do seznamu nainstalovaných aplikací (Start/Nastavení/Ovládací panely/Přidat nebo odebrat programy), odkud lze kdykoliv snadno odinstalovat.

Po úspěšné instalaci se objeví informační dialog (Obrázek A.5.) a v nabídce START/Programy vznikne zástupce pro spuštění aplikace (DISClient.exe).

Nechce-li uživatel instalovat aplikaci standardním způsobem, postačí když z instalačního CD zkopíruje adresář DISClient a spuštění poté provede souborem DISClient.exe.
Odinstalování aplikace se provede klasickým způsobem - použitím volby Přidat nebo odebrat programy z Ovládacích panelů.
Instalační soubor je vytvořen pomocí nové technologie „Windows Installer“. Místo toho, aby každý produkt měl vlastní instalační program, je instalace prováděna pomocí tzv. instalační databáze (soubor s příponou .MSI). Tato databáze obsahuje informace o tom, kam se má produkt instalovat, jaké přípony se mají registrovat a další.
V případě instalace produktu na starší operační systém, kde ještě tato technologie není zavedena, je potřeba ji dodatečně nainstalovat (potřebný instalátor lze najít na stránkách Microsoftu případně na instalačním CD v adresáři Servis, soubor InstMsi.exe).
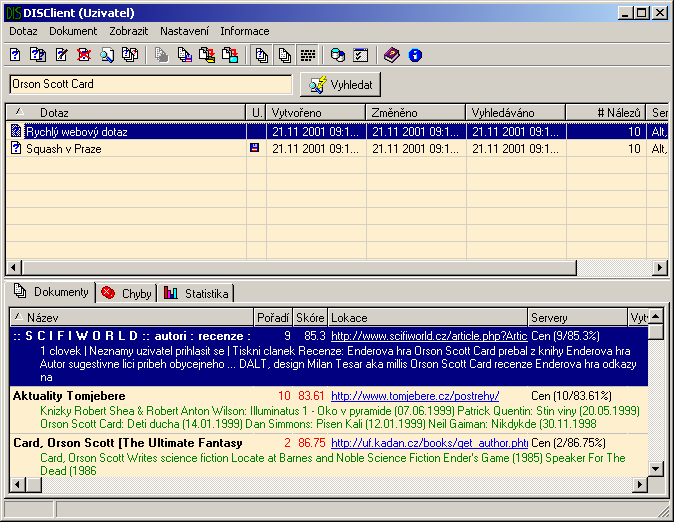
Hlavní okno aplikace (Obrázek A.6.) se skládá z několika částí: hlavní nabídka, která se nachází v horní části okna. Hned pod ní je panel nástrojů, který obsahuje nejčastěji používané akce z hlavní nabídky. Panel pro rychlé vyhledávání se vstupním políčkem pro zadání hledaného výrazu a tlačítkem pro vlastní vyhledávání.
Největší část okna zabírá přehled dotazů a seznam nalezených dokumentů. který se váže k označenému dotazu v přehledu. Nejspodnější část okna zabírá stavový řádek, který zobrazuje informace o aktuálně vybraném tlačítku v panelu nástrojů nebo o položce v hlavní nabídce.
Prvním krokem při používání aplikace DISClient je přihlášení uživatele do systému. Toto umožňuje každému uživateli nastavit si pracovní prostředí dle svých zvyků, umožní mu nastavit si vlastní servery, vlastní historii dotazů atd.
Při startu aplikace se objeví přihlašovací obrazovka s logem (Obrázek A.7.), která nabízí seznam uživatelů. Samozřejmě je zde také možnost vytvořit zcela nového uživatele.
Jiný způsob přihlášení je spuštění aplikace s parametrem, který představuje jméno uživatele:
DISClient.exe UŽIVATEL.
Jelikož je hlavním posláním aplikace usnadnit vyhledávání, je nejdůležitějším prvkem vlastní dotaz.
Nový dotaz se vytvoří za pomoci položky Dotaz/Nový dotaz v hlavní nabídce, případně lze použít odpovídající tlačítko v panelu nástrojů.
Prvním krokem je zadání názvu dotazu (ten slouží jen pro jeho identifikaci v seznamu dotazů). Zvolení počtu dokumentů, které si při vyhledávání aplikace vyžádá od každého osloveného serveru. A případně je možné zapsat poznámku (Obrázek A.8.).
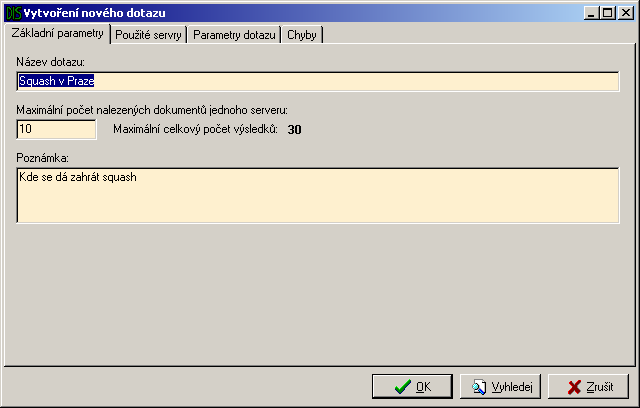
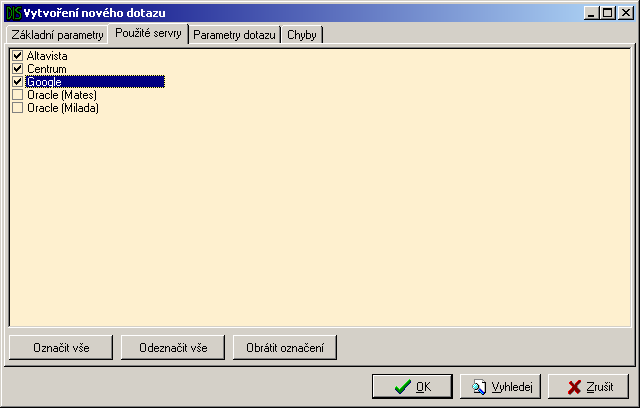
Druhým krokem je výběr serverů (Obrázek A.9.), které budou zadaný dotaz vyhodnocovat. Některé servery se musí před vlastním použitím inicializovat (například Oracle). Toto může trvat delší dobu, ale děje se tak jen při prvním využití serveru. Průběh připojování se zobrazuje ve zvláštním okně. Podle toho, které servery zde budou vybrány, bude vypadat strom parametrů dotazu v dalším kroku.
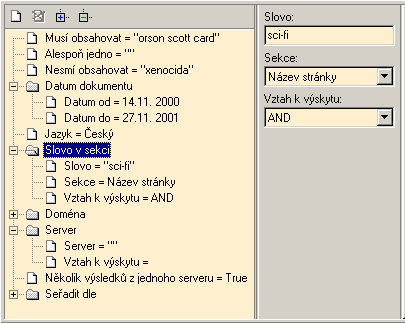
Na další záložce je zobrazen strom parametrů dotazu (Obrázek A.10.). Dotazy jsou dvojího typu. Jednoduché, představující jedinou hodnotu (například parametr „Jazyk“ pro specifikaci jazyku dokumentu) nebo skupinové. Ty reprezentují skupinu několika jednoduchých parametrů společně popisující jednu vlastnost hledaného dokumentu (například parametr „Datum dokumentu“ pro vymezení intervalu vzniku dokumentu nebo parametr „Slovo v sekci“, který popisuje která slova se musí, případně nesmí, v které sekci vyskytovat).
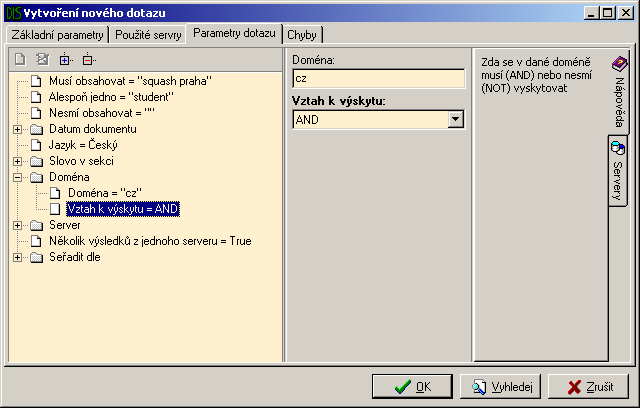
Po vybrání parametru se v prostřední části okna objeví příslušná editační políčka pro vyplnění jeho hodnoty (hodnot).
Někdy je potřebné vyplnit více parametrů stejného typu. Například při specifikaci výše zmíněného parametru „Slovo v sekci“ může uživatel potřebovat zadat jedno slovo, které se musí nacházet v určité sekci a zároveň ještě chce aby hledaný dokument neobsahoval nějaké jiné slovo v jiné sekci. Toto lze samozřejmě u některých parametrů (u kterých to má smysl) provést. Slouží k tomu jednak položka Přidej parametr v kontextové nabídce parametru, případně této položce odpovídající tlačítko nad stromem. Nově vytvořený parametr bude obsahovat stejné hodnoty jako originál. Libovolný nově vytvořený parametr, či jeho originál, lze obdobně smazat (položka Smaž parametr).
Poslední dvě tlačítka v této nástrojové liště slouží pro kompletní rozbalení, případně sbalení, stromové struktury parametrů.
Pravá část dialogu zobrazuje pomocné informace o aktuálně vybraném parametru. První záložka zobrazuje nápovědu, druhá přehled serverů, které daný parametr využívají. Výběr serverů se zde nedá změnit, to lze provést v dialogu pod záložkou Použité servery viz předcházející krok.
V okamžiku, kdy je uživatel spokojen s dotazem, potvrdí dialog tlačítkem OK, případně Vyhledej (pokud dotaz neobsahuje žádnou chybu, program se pokusí ihned začít vyhledávat). V tomto okamžiku se provede kontrola uživatelem zadaných dat a pokud se naleznou nějaké chyby, nabídne uživateli jejich zobrazení v poslední záložce tohoto dialogu (Obrázek A.11.).
Tato poslední záložka obsahuje seznam chyb a informace o nich (popis, který server ji nalezl, kterého parametru se týká a případně další informace v poznámce - typicky jak bude chybný parametr zpracován v případě, že nebude opraven).
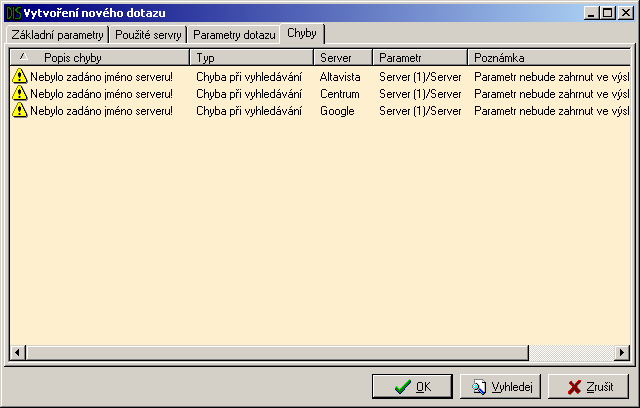
Rozhodne-li se uživatel chybu opravit, stačí na ni poklepat a dialog se automaticky přepne na předchozí záložku a nalezne tento parametr ve stromu.
Neobsahuje-li dotaz žádné chyby, je připraven pro vyhledání dokumentů, které tomuto dotazu odpovídají. Dokumenty budou hledány pomocí serverů, jež byly vybrány v druhém kroku.
Jiný způsob vytvoření nového dotazu je jeho odvození od stávajícího. Vznikne tak totožná kopie originálního dotazu. Toto je zejména výhodné, když se uživatel rozhodne ladit dotaz, ale chce si ponechat jeho kopii, aby se k němu mohl později v případě neúspěchu vrátit.
Existuje ještě jeden způsob vytvoření nového dotazu. Stačí do vstupního pole pod panelem nástrojů zadat řetězec, jež se má vyhledat a potvrdit tlačítkem Vyhledat. Parametry nově vytvářeného dotazu lze vyplnit v „šabloně“, která se nachází v nastavení. Nově vytvořený dotaz se zařadí do seznamu a ihned se začne vyhledávat.
Vyhledávání dokumentů se spustí buď za pomoci položky Dotaz/Vyhledat v hlavní nabídce případně odpovídajícím tlačítkem v nástrojové liště a nebo tlačítkem Vyhledat přímo v dialogu pro editaci dotazu. V případě, že se s některými servery ještě nepracovalo, proběhne jejich inicializace (například Oracle).
V následujícím dialogu (Obrázek A.12.) se zobrazuje postup vyhledávání na jednotlivých serverech. Pod názvem serveru je vždy combobox se zprávami o průběhu. Při ukončení hledání obsahuje toto políčko mimo jiné počet nalezených dokumentů. Hledání lze kdykoliv ukončit tlačítkem Stop. Změní-li se popiska tohoto tlačítka na Ok znamená to, že vyhledávání bylo ukončeno.
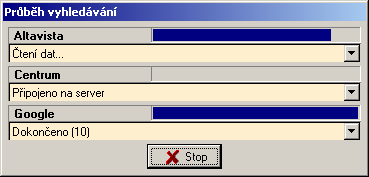
Nyní se ve spodní části hlavního okna, pod seznamem dotazů, zobrazí přehled nalezených dokumentů (Obrázek A.13.). Tento seznam obsahuje o každém nalezeném dokumentu několik informací:
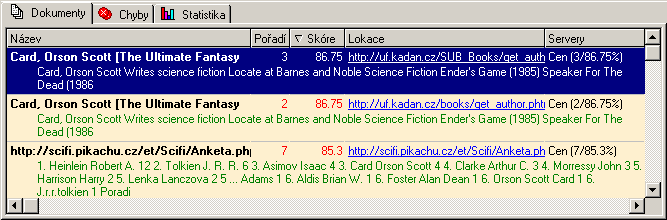
Celkové pořadí a skóre, které dokument dosáhl. Pokud jeden a ten samý dokument byl nalezen více servery, tyto hodnoty představují průměrnou hodnotu. Hodnoty, které dokument dosáhl na jednotlivých serverech jsou uvedeny ve sloupečku Servery. Zde je třeba poznamenat, že ne každý server vrací ohodnocení nalezených dokumentů.
Lokace dokumentu může představovat například URL adresu nebo jiný identifikátor dokumentu (například v případě Oraclu je to jméno tabulky a hodnota primárního klíče dokumentu).
Seznam zkratek serverů, které našly dokument s uvedením pořadí a skóre, jež dokument na těchto serverech dosáhl.
Datumy vytvoření a modifikace dokumentu (pokud se tyto informace podařilo zjistit).
Ukázka z dokumentu se zobrazuje pod výše uvedenými informacemi. Zobrazování této ukázky je možno vypnout pomocí volby Zobrazit/Ukázka dokumentu.
Spodní část okna obsahuje i další informace o průběhu vyhledávání, které jsou schovány pod dalšími záložkami:
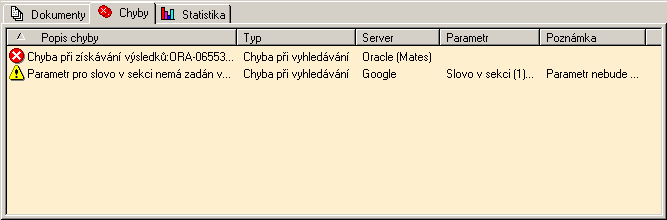
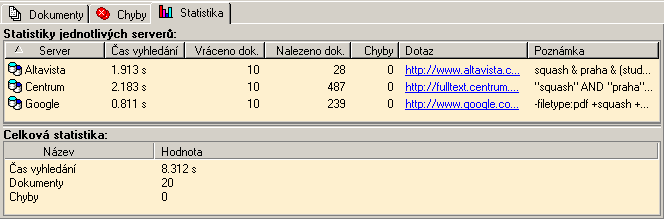
- Chyby
Seznam chyb (Obrázek A.14.), ke kterým došlo v průběhu vyhledávání, případně chyby, které nebyly opraveny při editaci dotazu.
- Statistika
Obsahuje informace o celkové době hledání, počtu nalezených dokumentů, počtu chyb (Obrázek A.15.). A také o tom, jak úspěšné byly jednotlivé servery:
Kolik dokumentů celkem odpovídalo položenému dotazu (z těchto bylo pouze několik prvních vráceno).
Dotaz položený serveru. Tento řetězec obsahuje dotaz jak jej server dostal. Pro každý server je tento dotaz odlišný. Jedná-li se například o webový fulltextový vyhledávač, je dotazem URL vyhledávacího stroje, která je doplněna příslušnými parametry. V takovém případě se po poklikání otevře asociovaný Internetový prohlížeč a zobrazí HTML stránku obsahující nalezené dokumenty, kterou oslovený server vrátil. Naopak například v případě Oracle serveru obsahuje toto políčko SQL dotaz.
Poznámka obsahuje případný dodatek k vlastnímu dotazu, případně další doplňující informace.
Dialog pro nastavení (Obrázek A.16.) umožňuje nastavit základní vlastnosti aplikace. Jedná se zejména o parametry rychlého hledání, zobrazování seznamu dokumentů a nastavení serverů.
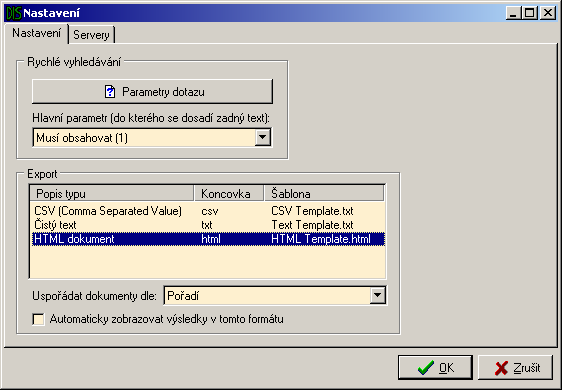
Tlačítko Parametry dotazu na první záložce slouží k nastavení šablony dotazu pro rychlé vyhledávání. Lze tak nastavit veškeré parametry dotazu. Hledaný řetězec (to co uživatel zadá) se dosadí do parametru, který je vybrán v comboboxu pod tímto tlačítkem.
Dále zde lze ještě určit jak se má zobrazovat uživateli seznam nalezených dokumentů při rychlém exportu. Na výběr je stejný seznam formátů jako při exportu (oddíl nazvaný „Seznamy dokumentů, export“). Navíc lze zvolit automatické zobrazování, které zapříčiní okamžité zobrazení nalezených dokumentů po vyhledání ve zvoleném formátu za použití asociovaného prohlížeče. To využijí uživatelé zejména v tom případě, že se jim nelíbí stávající zobrazování. Vzhled výsledného dokumentu lze změnit pozměněním stávající šablony nebo vytvořením nové (viz oddíl nazvaný „Vlastní šablona pro export“).
Druhá záložka (Obrázek A.17.) umožňuje nastavit veškeré parametry všech dostupných serverů. S tímto dialogem se pracuje obdobně jako při specifikaci parametrů dotazu.
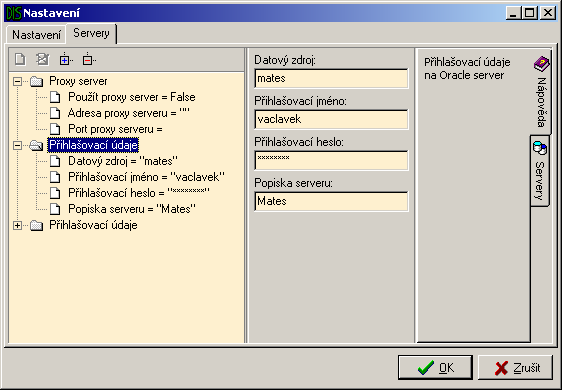
V současnosti lze nastavit parametry proxy serveru pro webové vyhledávače a přihlašovací údaje pro Oracle server. Poslední položka v této skupině parametrů (Popiska serveru) je uživatelský název serveru. Tento název bude ve všech seznamech identifikovat server.
Seznamy nalezených dokumentů lze samozřejmě uložit pro pozdější práci (položka Dokument/Uložit seznam dokumentů) a zpětně načíst (položka Dokument/Načíst seznam dokumentů). O tom, zda k dotazu existuje uložený seznam nalezených dokumentů informuje uživatele malá ikona diskety ve druhém sloupci přehledu.
Jiným způsobem uložení seznamu dokumentů je jeho export (Dokument/Export seznamu dokumentů). Exportovat lze do několika formátů:
- HTML dokument (html)
Report vygenerovaný jako HTML stránka s použitím kaskádových stylů
- Comma Separated Value (csv)
Tento formát lze načíst do většiny tabulkových programů jako je například Microsoft Excel (kde lze s daty dále pracovat). Jednotlivé hodnoty jsou ve výstupním souboru odděleny čárkou, věty jsou odděleny odřádkováním.
- Čistý text (txt)
Univerzální formát, neobsahuje žádné formátovací tagy, lze prohlížet na libovolné platformě.
Pro vlastní export (Obrázek A.18.) stačí vybrat požadovaný formát, zadat jméno souboru (koncovka je nepovinná, pokud nebude uvedena, doplní se automaticky dle vybraného formátu) a pořadí v jakém mají být dokumenty na výstupu uspořádány. Po úspěšném vygenerování je možno výsledek ihned prohlédnout pomocí asociovaného prohlížeče.
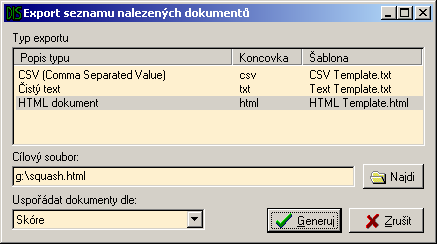
Uživatel může také využít „rychlý export“, který slouží pouze pro prohlížení výsledků (výsledek se ukládá do pomocného adresáře). Není třeba opakovaně zadávat vlastnosti tohoto exportu (ty lze editovat v nastavení viz oddíl nazvaný „Nastavení“).
V aplikaci lze mírně měnit vzhled zobrazování. Veškeré volby tohoto se týkající se nachází v podnabídce Zobrazit. Lze vypnout zobrazování ukázky dokumentu (v seznamu dokumentů zabírá téměř vždy nejvíce místa), lze vypnout zobrazování seznamu dokumentů případně seznamu dotazů.
Spíše pro vývojáře dalších DLL knihoven rozšiřujících spektrum vyhledávajících služeb je určen přehled (Obrázek A.19.) všech implementovaných parametrů (Informace/Seznam parametrů).
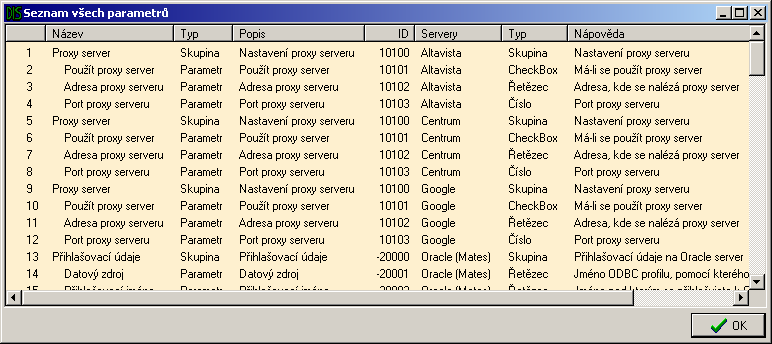
Pro přehlednější a rychlejší práci s aplikací je vhodné používat více seznamů dokumentů. Dotazy tak budou rozumně uspořádány a také se tím zrychlí start a ukončení aplikace, kdy dochází k načítání a ukládání historie dotazů.
Přehled seznamů dotazů (Obrázek A.20.) se nachází pod položkou Dotaz/Seznamy dotazů. V tomto přehledu lze vytvořit nový, smazat stávající, či nastavit zvolený seznam jako aktuální.
Základními prvky celé aplikace jsou servery, které se využívají při vyhledávání. Jejich seznam (Obrázek A.21.) je přístupný přes položku Nastavení/Dostupné servery. V seznamu jsou uvedeny nejen jejich názvy, ale i zkratky, které se zobrazují v některých stručnějších výpisech, DLL knihovna, ve které jsou implementovány a další informace.
Některé servery umožňují svou duplikaci a tím rozšiřují řadu použitelných zdrojů. Jedním z příkladů je server Oracle. Vytvořením jeho další kopie (tlačítko Nový server, které je povolené v okamžiku, kdy je vybrán server umožňující vytváření svých kopií) vznikne další plnohodnotný zdroj pro vyhledávání, který se od originálu liší nastavením (to je možno upravit v dialogu Nastavení/Nastavení). Duplicitní servery lze samozřejmě také smazat (tlačítko Smazat server).
Dalším způsobem, jak rozšířit množinu použitelných serverů je získání další DLL knihovny a to buď od výrobce programu nebo od kohokoliv jiného. Nové knihovny je třeba nahrát do adresáře Servers, který je v adresáři obsahující program (DISClient.exe).
Výběr formátů na export je v dodávané verzi aplikace omezený (HTML, CSV, TXT). Uživatel si ale může kdykoliv vytvořit vlastní novou šablonu pro export do libovolných dalších formátů (XML, TEX, TXT, …).
Tuto šablonu (textový soubor, jehož popis bude následovat dále) je třeba uložit do podadresáře Export Templates adresáře, kde se nachází vlastní exe soubor aplikace. Na jeho jméně a koncovce nezáleží.
Šablonu exportu tvoří jednoduchý textový soubor, který kromě vlastního formátování výstupního exportu (například HTML tagy v případě HTML exportu) obsahuje i speciální tagy, které aplikace nahradí příslušnými daty. Tyto tagy mají následující syntaxi:
<#JMENO_TAGU JMENO_ATRIBUTU='HODNOTA'>.
Tabulka A.1. Názvy a popisy tagů šablony
| Název tagu | Význam |
|---|---|
| ACT_DATE | Aktuální datum a čas (tedy datum a čas exportu) |
| USER_NAME | Jméno aktuálně přihlášeného uživatele |
| DOC_COUNT | Počet nalezených dokumentů |
| Tagy reprezentující vlastnosti dotazu | |
| QNAME | Název dotazu |
| QCREATED | Datum a čas vytvoření dotazu |
| QEDITED | Datum a čas poslední modifikace dotazu |
| QSEARCHED | Datum a čas posledního vyhledávání dokumentů odpovídajících dotazu |
| QTOTAL_COUNT | Maximální počet nalezených dokumentů z jednoho serveru |
| QSERVER_COUNT | Počet dotazem využívaných serverů |
| QSERVERS | Seznam serverů, které dotaz používá pro vyhledávání |
| QNOTE | Poznámka k dotazu |
| Tagy reprezentující vlastnosti dokumentu | |
| DNUM | Aktuální číslo dokumentu |
| DNAME | Název dokumentu |
| DLOCATION | Lokace dokumentu |
| DSCORE | Celkové skóre dosažené dokumentem |
| DORDNUM | Celkové pořadí dokumentu |
| DCREATED | Datum vytvoření dokumentu |
| DMODIFIED | Datum poslední změny dokumentu |
| DEXTRACT | Ukázka z dokumentu |
| DNOTE | Poznámka k dokumentu |
| DSERVERINFOS | Informace o hodnocení dokumentu servery, které jej nalezly |
| Speciální tagy | |
| TEMPLATE_INFO | Tag popisující vlastní šablonu, musí být uveden na začátku souboru (tedy jako první tag), má dva atributy viz popis dále. |
| LIST_BEGIN | Tag označující začátek smyčky, která obsahuje všechny nalezené dokumenty. Mezi tagy LIST_BEGIN a LIST_END by měly být uvedeny tagy popisující dokument, které budou nahrazeny skutečnými vlastnostmi nalezených dokumentů. |
| LIST_END | Konec smyčky dokumentů |
Rozšiřující atributy jsou použity pouze u jediného tagu TEMPLATE_INFO, který popisuje šablonu a musí být uveden na samém začátku souboru. Popis atributů tohoto tagu:
- Ext
Koncovka, s jakou se bude soubor ukládat (html, txt, xml, …). Tato koncovka je poměrně důležitá, neboť to bude výchozí koncovka, pokud uživatel nezapíše jinou a jednak se na zobrazení výsledného exportu použije prohlížeč, který je s touto koncovkou asociován.
- Name
Jméno (může být i s krátkým komentářem) pod jakým bude šablona uvedena v seznamu dostupných formátů pro export.
Tabulka A.2. Klávesové zkratky
| Klávesová zkratka | Popis |
|---|---|
| Ctrl+N | Nový dotaz |
| Ctrl+D | Odvodit nový dotaz |
| Ctrl+E | Editace dotazu |
| Shift+Del | Smazání dotazu |
| Ctrl+F | Vyhledat |
| Ctrl+S | Uložit seznam dokumentů |
| Ctrl+O | Načíst seznam dokumentů |
| Ctrl+T | Zobrazit seznam šablonou |
| Ctrl+F1 | Informace o aplikaci |
| F1 | Nápověda |
| Ins | Přidání parametru (ve stromě parametrů) |
- Index.htm
- DISClient.msi
- [DISClient]
Adresář obsahující vlastní aplikaci, která se nemusí instalovat (stačí obsah tohoto adresáře překopírovat na cílové místo na disku) a spustit souborem DISClient.exe.
- [Documents]
Dokumentace k programu a vlastní diplomová práce v několika formátech (.rtf, .pdf, .html).
- [Servis]
Několik nástrojů, které by mohl uživatel potřebovat (Oracle8i klient, Adobe Acrobat Reader 5.0, Windows Installer Engine pro starší operační systémy).
- [Source]